
ElasticSearch là một công cụ mạnh mẽ cho phân tích văn bản (text analysis). Text analysis trong ElasticSearch bao gồm các quá trình xử lý và phân tích dữ liệu văn bản để tìm kiếm, lập chỉ mục và truy vấn một cách hiệu quả. Các thành phần chính của text analysis trong ElasticSearch bao gồm:
- Character Filters: Các bộ lọc ký tự xử lý văn bản thô bằng cách thực hiện các thao tác như loại bỏ hoặc thay thế ký tự trước khi văn bản được phân tích tiếp theo.
- Tokenizers: Bộ tách từ cắt văn bản thành các đơn vị nhỏ hơn gọi là tokens. Ví dụ, bộ tách từ có thể chia một chuỗi văn bản thành các từ riêng lẻ.
- Token Filters: Sau khi văn bản được tách thành các token, các bộ lọc token có thể sửa đổi các token này. Các thao tác có thể bao gồm chuyển đổi chữ hoa thành chữ thường, loại bỏ từ dừng (stop words), tạo ra các token từ gốc (stemming), hoặc mở rộng từ (synonym expansion).
Các thành phần chính của một Analyzer
Một Analyzer trong ElasticSearch là một tập hợp của các thành phần sau:
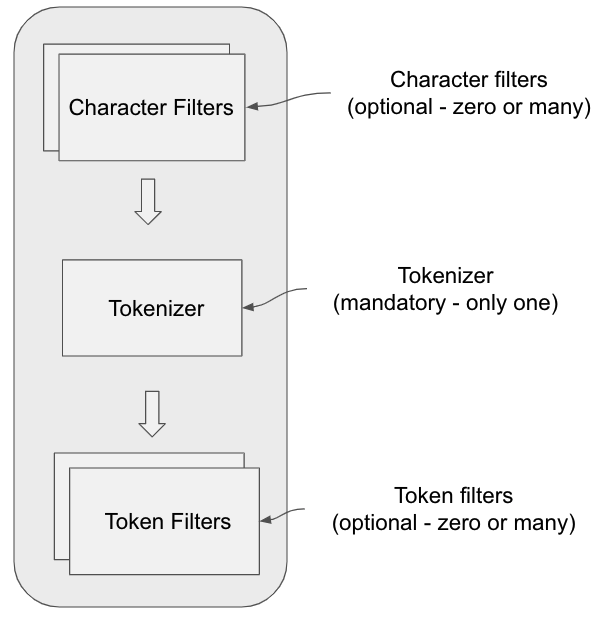
- Character Filters:
- Loại bỏ hoặc thay thế các ký tự đặc biệt trong văn bản.
- Thực hiện các thao tác như chuyển đổi HTML entities sang ký tự thực tế.
- Tokenizer:
- Chia văn bản thành các token dựa trên khoảng trắng, dấu câu, hoặc các quy tắc tùy chỉnh.
- Ví dụ:
whitespace tokenizer,standard tokenizer,pattern tokenizer.
- Token Filters:
- Chỉnh sửa các token đã được tạo bởi tokenizer.
- Một số bộ lọc phổ biến:
Lowercase Token Filter: chuyển đổi các token thành chữ thường.Stop Token Filter: loại bỏ các từ dừng phổ biến như “and”, “the”.Stemmer Token Filter: chuyển đổi các từ về dạng gốc của chúng.Synonym Token Filter: thay thế các token bằng các từ đồng nghĩa.
Quy trình phân tích văn bản trong ElasticSearch
- Nhận văn bản đầu vào: Văn bản gốc được đưa vào quy trình phân tích.
- Character Filters: Văn bản đầu vào được xử lý qua các bộ lọc ký tự.
- Tokenizer: Văn bản đã qua xử lý được chia thành các token.
- Token Filters: Các token được lọc và chỉnh sửa.
- Lưu trữ và tìm kiếm: Các token đã qua xử lý được lập chỉ mục và lưu trữ trong ElasticSearch để phục vụ cho việc tìm kiếm và truy vấn.
Dưới đây là các ví dụ cụ thể để minh họa cho từng thành phần và quy trình phân tích văn bản trong ElasticSearch.
1. Character Filters
Ví dụ: Sử dụng HTML Strip Character Filter để loại bỏ các thẻ HTML trong văn bản.
Văn bản đầu vào:
<h1>Hello World!</h1>Character Filter: HTML Strip Character Filter
Văn bản sau xử lý:
Hello World!2. Tokenizers
Ví dụ: Sử dụng Whitespace Tokenizer để tách văn bản dựa trên khoảng trắng.
Văn bản đầu vào:
Hello World! This is ElasticSearch.Tokenizer: Whitespace Tokenizer
Các token kết quả:
["Hello", "World!", "This", "is", "ElasticSearch."]3. Token Filters
Ví dụ 1: Sử dụng Lowercase Token Filter để chuyển đổi tất cả các token thành chữ thường.
Các token đầu vào:
["Hello", "World!", "This", "is", "ElasticSearch."]Token Filter: Lowercase Token Filter
Các token kết quả:
["hello", "world!", "this", "is", "elasticsearch."]Ví dụ 2: Sử dụng Stop Token Filter để loại bỏ các từ dừng phổ biến.
Các token đầu vào:
["hello", "world!", "this", "is", "elasticsearch."]Token Filter: Stop Token Filter
Các token kết quả:
["hello", "world!", "elasticsearch."]Ví dụ 3: Sử dụng Stemmer Token Filter để chuyển đổi các từ về dạng gốc.
Các token đầu vào:
["running", "jumps", "easily"]Token Filter: Stemmer Token Filter
Các token kết quả:
["run", "jump", "easili"]Ví dụ 4: Sử dụng Synonym Token Filter để thay thế các token bằng từ đồng nghĩa.
Các token đầu vào:
["quick", "jumps"]Token Filter: Synonym Token Filter (cấu hình từ đồng nghĩa: quick => fast)
Các token kết quả:
["fast", "jumps"]Quy trình phân tích văn bản trong ElasticSearch
Ví dụ tổng hợp: Phân tích văn bản “The quick brown fox jumps over the lazy dog.”
Văn bản đầu vào:
The quick brown fox jumps over the lazy dog.- Character Filters: Không áp dụng trong ví dụ này.
- Tokenizer: Standard Tokenizer
Các token kết quả: [“The”, “quick”, “brown”, “fox”, “jumps”, “over”, “the”, “lazy”, “dog”] - Token Filters:
- Lowercase Token Filter:
["the", "quick", "brown", "fox", "jumps", "over", "the", "lazy", "dog"] - Stop Token Filter:
["quick", "brown", "fox", "jumps", "lazy", "dog"] - Synonym Token Filter (cấu hình từ đồng nghĩa: quick => fast):
["fast", "brown", "fox", "jumps", "lazy", "dog"]
- Lowercase Token Filter:
Các token cuối cùng sau quá trình phân tích:
["fast", "brown", "fox", "jumps", "lazy", "dog"]Qua các ví dụ trên, bạn có thể thấy cách từng thành phần của một analyzer hoạt động và ảnh hưởng đến quá trình phân tích văn bản trong ElasticSearch.
Tổng kết
ElasticSearch cung cấp nhiều công cụ và tùy chọn cấu hình để người dùng có thể tùy chỉnh quy trình phân tích văn bản theo nhu cầu cụ thể của mình. Việc hiểu rõ các thành phần của một analyzer và cách chúng hoạt động cùng nhau là chìa khóa để tối ưu hóa hiệu quả tìm kiếm và truy vấn văn bản trong ElasticSearch.
Extra reading
https://ant.ncc.asia/elasticsearch-p1-elasticsearch-hoat-dong-ra-sao/
https://ant.ncc.asia/elasticsearch-p2-cai-dat-va-cau-hinh/
https://ant.ncc.asia/elasticsearch-p3-querying-va-searching/
https://ant.ncc.asia/elasticsearch-p4-quan-ly-va-toi-uu-hoa-hieu-suat/
https://ant.ncc.asia/elasticsearch-p5-bao-mat-va-quan-ly-nguoi-dung/
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-overview.html


One Reply to “Tổng quan về Text analysis trong Elasticsearch”