
Giới thiệu
Trong bài viết này, chúng ta sẽ tìm hiểu cách hoạt động tính năng Auto explain của PostgreSQL. Hiểu lý do tại sao bạn nên sử dụng nó để thu thập kế hoạch thực thi thực tế cho các câu lệnh SQL trên hệ thống production.
SQL Execution Plan
Khi bạn gửi một câu lệnh SQL tới PostgreSQL, câu lệnh đó sẽ được thực thi như được minh họa bằng sơ đồ sau:
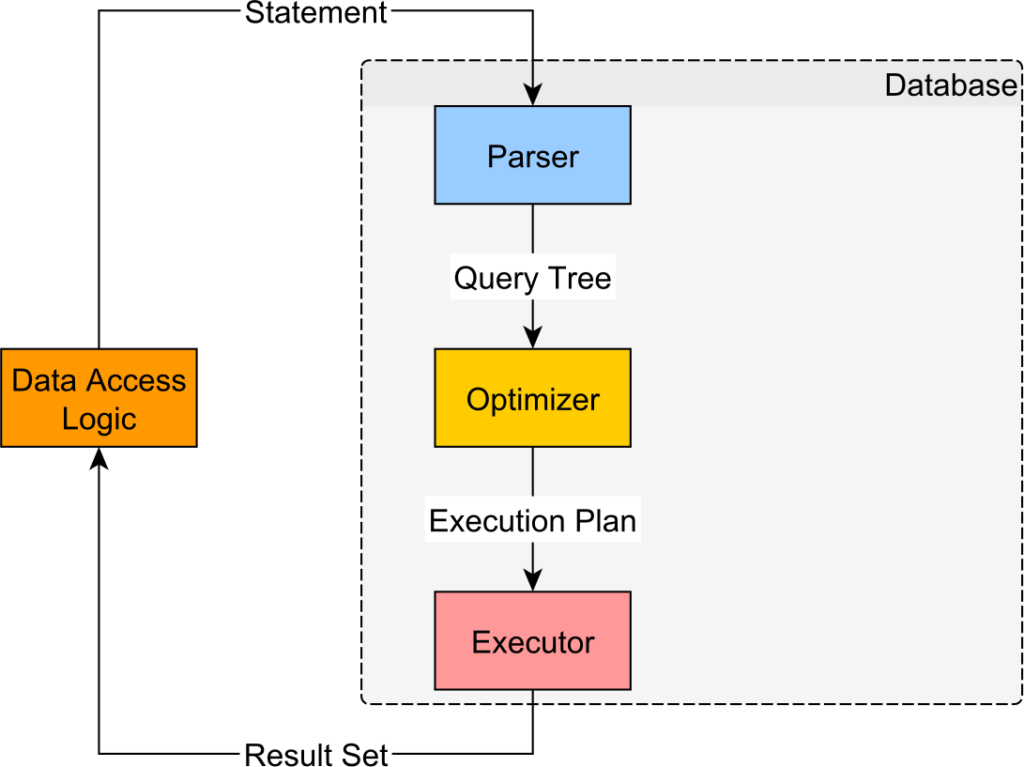
Đầu tiên, câu lệnh SQL dựa trên văn bản được phân tích cú pháp thành Abstract Syntax Tree (ví dụ: Query tree) mà máy chủ cơ sở dữ liệu có thể duyệt qua theo chương trình.
Thứ hai, Trình tối ưu hóa sử dụng Query tree để tạo Execution Plan tối ưu tiêu tốn ít tài nguyên nhất để tạo ra kết quả mong muốn.
Thứ ba, Executor chạy Execution Plan và kết quả đầu ra được trả về client dưới dạng Result set.
Estimated vs. Actual Execution Plan
Khi bạn đang sử dụng lệnh EXPLAIN. PostgreSQL chỉ trả về Estimated Execution Plan, kế hoạch mà Optimizer cho rằng hiệu quả nhất đối với câu lệnh SQL được cung cấp. Tuy nhiên, câu lệnh không thực sự được thực thi khi bạn chạy lệnh EXPLAIN.
Mặt khác, nếu chúng ta chạy EXPLAIN ANALYZE, PostgreSQL chạy câu lệnh nên chúng ta sẽ nhận được Actual Execution Plan, kế hoạch này cũng chứa thông tin về thời gian cho từng thao tác trong kế hoạch thực hiện.
Khi điều tra một truy vấn chậm trên hệ thống production, chúng ta có thể gặp phải một số thách thức.
Đầu tiên, vì lý do bảo mật, chúng tôi có thể không được phép chạy truy vấn trên hệ thống production, vì vậy, trong trường hợp đó, chúng ta không thể chỉ chạy lệnh EXPLAIN ANALYZE để lấy Kế hoạch thực thi thực tế.
Thứ hai, ngay cả khi chúng ta có đặc quyền chạy lệnh EXPLAIN ANALYZE, chúng ta có thể quan sát một kế hoạch khác với kế hoạch mà khách hàng đã phàn nàn. Điều này có thể là do một số lý do.
Chẳng hạn, PostgreSQL có cài đặt prepareThreshold , có giá trị mặc định là 5. Giá trị này cho PostgreSQL biết số lần nó có thể mô phỏng Prepared Statement ở phía client trước khi chuyển sang Prepared Statement phía server sử dụng một gói chung.
Nếu truy vấn chậm đang sử dụng một kế hoạch chung, bạn có thể không nhận được kế hoạch tương tự ngay cả khi bạn chạy EXPLAIN ANALYZE, việc này sẽ tạo ra một kế hoạch thực hiện nhanh chóng.
Vì vậy, giải pháp tốt hơn nhiều để phân tích các truy vấn chậm là nếu chúng ta lấy Actual Execution Plan đã được PostgreSQL sử dụng khi chạy truy vấn được đề cập.
PostgreSQL Auto Explain module
PostgreSQL có khả năng tùy chỉnh rất cao và nó cung cấp một số tiện ích mở rộng mà chúng ta có thể kích hoạt một cách rõ ràng.
Một tiện ích mở rộng như vậy là auto_explain, cho phép chúng tôi nắm bắt Actual Execution Plan của một truy vấn SQL mất nhiều thời gian hơn giá trị ngưỡng được xác định trước.
Nếu bạn muốn kích hoạt tiện ích auto_explain mở rộng trên máy chủ cơ sở dữ liệu PostgreSQL thì bạn có thể kích hoạt tiện ích mở rộng này trong postgresql.conf tệp cấu hình thông qua cài đặt session_preload_libraries:
session_preload_libraries = 'auto_explain'Sau đó, bạn có thể xác định ngưỡng truy vấn chậm. Ví dụ: nếu chúng tôi muốn nắm bắt Actual Execution Plan của tất cả các truy vấn mất hơn 100mili giây thì chúng ta cần cung cấp cài đặt PostgreSQL sau:
auto_explain.log_analyze = 'on'
auto_explain.log_min_duration = '100ms'Sau khi kích hoạt tính năng Auto Explain của PostgreSQL và chạy một số truy vấn SQL mất hơn 100mili giây, chúng tôi sẽ nhận được các mục sau vào nhật ký PostgreSQL:
LOG: duration: 216.952 ms plan:
Query Text:
SELECT
university_name
FROM scholarship_criteria
WHERE admission_score <= ANY (
SELECT
AVG(student_grade.grade)
FROM student_grade
GROUP BY student_id
)
ORDER BY id
Nested Loop Semi Join
(cost=0.55..20075.80 rows=1 width=17)
(actual time=216.944..216.946 rows=1 loops=1)
Join Filter: (scholarship_criteria.admission_score <= (avg(student_grade.grade)))
Rows Removed by Join Filter: 121266
-> Index Scan using scholarship_criteria_pkey on scholarship_criteria
(cost=0.13..12.16 rows=2 width=25)
(actual time=0.038..0.039 rows=2 loops=1)
-> GroupAggregate
(cost=0.42..17798.42 rows=100640 width=16)
(actual time=0.046..104.982 rows=60634 loops=2)
Group Key: student_grade.student_id
-> Index Scan using idx_student_grade_student_id on student_grade
(cost=0.42..14040.42 rows=500000 width=16)
(actual time=0.040..51.788 rows=303168 loops=2)
One Reply to “Tìm hiểu PostgreSQL Auto Explain”