Khi việc áp dụng Kubernetes tiếp tục gia tăng, nhu cầu về các phương pháp giám sát mạnh mẽ cũng tăng theo. Kubernetes đơn giản hóa việc triển khai, mở rộng và quản lý các ứng dụng container hóa, nhưng bản chất động và thoáng qua của nó mang lại nhiều thách thức. Giám sát hiệu quả là chìa khóa để duy trì hiệu suất và bảo mật của các môi trường Kubernetes. Hướng dẫn toàn diện này sẽ trình bày tầm quan trọng của việc giám sát Kubernetes, khám phá các công cụ phổ biến, và nêu rõ các phương pháp tốt nhất để đảm bảo hoạt động trơn tru trong các môi trường container hóa.
Giới thiệu
Chính những tính năng làm cho Kubernetes trở nên mạnh mẽ — chẳng hạn như tự động automatic scaling, self-healing và tính phân tán của các cụm — cũng tạo ra các phức tạp có thể cản trở hiệu suất nếu không được quản lý đúng cách. Giám sát Kubernetes là điều cần thiết để hiểu trạng thái của các ứng dụng, đảm bảo chúng hoạt động ổn định và phát hiện các vấn đề trước khi chúng leo thang thành các vấn đề nghiêm trọng.
Các ứng dụng, tài nguyên và node liên tục thay đổi khi chúng mở rộng hoặc thu hẹp quy mô, khởi động lại hoặc phân bổ lại tài nguyên. Giám sát những biến động này trong thời gian thực trở nên quan trọng để duy trì thời gian hoạt động của dịch vụ, tối ưu hóa việc sử dụng tài nguyên và ngăn chặn các sự cố tốn kém.
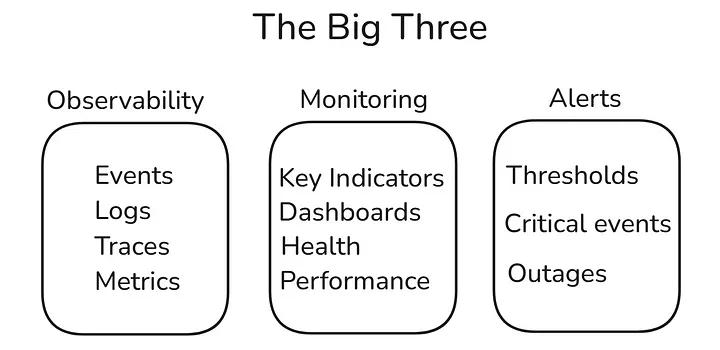
Hiểu đúng về Monitoring và Observability
Monitoring
Monitoring là việc thu thập, phân tích và sử dụng các tập hợp chỉ số hoặc nhật ký được định nghĩa trước. Nó liên quan đến việc theo dõi các vấn đề đã biết và giám sát các vấn đề đã xác định. Các khía cạnh chính của giám sát bao gồm:
Trong ngữ cảnh Kubernetes, giám sát có thể bao gồm việc theo dõi mức sử dụng CPU, tiêu thụ bộ nhớ, trạng thái của các pod và các chỉ số được định nghĩa trước khác mà bạn biết là quan trọng đối với sức khỏe của hệ thống.
- Tập trung vào các chỉ số và ngưỡng được định nghĩa trước
- Trả lời các câu hỏi đã biết về hành vi của hệ thống
- Thường sử dụng bảng điều khiển và cảnh báo
- Mang tính chất phản ứng, xử lý các vấn đề đã biết
Bốn tín hiệu vàng (The Four Golden Signals)
Khi triển khai giám sát, điều quan trọng là tập trung vào các chỉ số chính. “Bốn tín hiệu vàng” cung cấp một điểm khởi đầu vững chắc cho bất kỳ ứng dụng nào:
- Độ trễ (Latency): Đo lường thời gian cần thiết để một yêu cầu di chuyển từ phía khách hàng đến máy chủ và quay trở lại.
- Lưu lượng (Traffic): Chỉ số về số lượng yêu cầu mà hệ thống nhận được trong một khoảng thời gian cụ thể.
- Tỷ lệ lỗi (Error Rate): Đại diện cho tỷ lệ phần trăm các yêu cầu dẫn đến lỗi (ví dụ: lỗi 404, 500).
- Độ bão hòa (Saturation): Đo lường mức độ sử dụng tài nguyên, bao gồm CPU, bộ nhớ và không gian đĩa.
Các chỉ số này cung cấp một cái nhìn tổng quan ở cấp độ cao về sức khỏe của hệ thống và trải nghiệm của người dùng.
Các phương pháp tốt nhất để giám sát
- Triển khai giám sát càng sớm càng tốt trong chu kỳ phát triển.
- Tập trung vào “Bốn tín hiệu vàng,” sau đó mở rộng dựa trên nhu cầu cụ thể của ứng dụng.
- Đảm bảo bảng điều khiển và cảnh báo dễ hiểu và đi thẳng vào vấn đề.
- Hạn chế cảnh báo dựa trên mức độ ưu tiên để tránh hiện tượng “mệt mỏi vì cảnh báo” (alert fatigue).
Observability
Observability vượt xa giám sát (Monitoring) bằng cách cung cấp bối cảnh và cho phép bạn đặt ra các câu hỏi mà bạn chưa từng dự đoán trước. Đây là một thước đo về mức độ bạn có thể hiểu được trạng thái nội bộ của một hệ thống dựa trên các đầu ra bên ngoài của nó. Các khía cạnh chính của khả năng quan sát bao gồm:
- Cung cấp cái nhìn toàn diện về hệ thống
- Cho phép khám phá các vấn đề và hành vi chưa biết
- Kết hợp các chỉ số, nhật ký và truy vết để có những hiểu biết toàn diện
- Mang tính chất chủ động, giúp phát hiện các vấn đề chưa lường trước
The Three Pillars of Observability
Khả năng quan sát được xây dựng trên ba loại dữ liệu đo lường chính:
- Nhật ký (Logs): Cung cấp bản ghi theo thứ tự thời gian về các sự kiện hoặc giao dịch trong hệ thống.
- Chỉ số (Metrics): Cung cấp các phép đo định lượng thể hiện hiệu suất của hệ thống tại các thời điểm cụ thể.
- Truy vết (Traces): Giúp theo dõi luồng của các yêu cầu qua các dịch vụ và thành phần khác nhau trong hệ thống.
Các phương pháp tốt nhất để tăng cường khả năng quan sát
- Kiểm soát khối lượng nhật ký được thu thập để quản lý chi phí một cách hiệu quả.
- Đảm bảo rằng dữ liệu quan sát có đủ ngữ cảnh để hỗ trợ khắc phục sự cố hiệu quả.
- Triển khai chiến lược xóa các nhật ký không cần thiết theo thời gian.
Mối quan hệ giữa Monitoring và Observability
Mặc dù giám sát (Monitoring) và khả năng quan sát (Observability) là hai khái niệm riêng biệt, chúng hoạt động cùng nhau để duy trì sức khỏe của hệ thống:
- Monitoring cảnh báo khi có sự cố xảy ra.
- Observability giúp hiểu tại sao có lỗi và cách khắc phục nó.
- Monitoring thường được coi là một phần của observability.
- Cả hai đều quan trọng để duy trì một môi trường Kubernetes khỏe mạnh.
Minh họa sự khác biệt
Hãy tưởng tượng bạn đang giám sát các dấu hiệu sinh tồn của một bệnh nhân sau phẫu thuật. Đột nhiên, bạn nhận được cảnh báo rằng nhịp tim của bệnh nhân tăng cao bất thường. Đây là Monitoring — nhận cảnh báo rằng có thể có vấn đề.
Observability xuất hiện khi bác sĩ xem xét nhiều dữ liệu khác nhau, như hoạt động gần đây, lịch trình dùng thuốc và mẫu giấc ngủ của bệnh nhân. Dữ liệu này, được tạo ra trước cảnh báo nhịp tim, đóng vai trò là manh mối quan trọng để hiểu nguyên nhân gốc rễ. Sau đó, bác sĩ có thể xác định rằng thuốc giảm đau gây ra phản ứng dị ứng.
Trong thế giới phần mềm, Monitoring phát hiện các vấn đề như thời gian phản hồi tăng đột biến và cảnh báo chúng ta. Observability cho phép phân tích nhật ký, chỉ số và truy vết để tìm ra nguyên nhân gốc rễ.
Bằng cách triển khai cả hai phương pháp này trong môi trường Kubernetes, bạn có thể không chỉ phản ứng với các vấn đề đã biết mà còn chủ động xác định và giải quyết các vấn đề phức tạp trong hệ sinh thái của mình.
Tại sao giám sát Kubernetes lại khác biệt
Trước khi đi sâu vào các phương pháp tốt nhất, điều quan trọng là hiểu lý do tại sao việc giám sát Kubernetes khác với giám sát cơ sở hạ tầng truyền thống:
- Tài nguyên thoáng qua (Ephemeral Resources): Không giống như máy chủ truyền thống, các pod và node trong Kubernetes không phải là tĩnh. Chúng được thiết kế để tạo và hủy động theo nhu cầu công việc, gây khó khăn trong việc theo dõi hành vi và sức khỏe lâu dài của tài nguyên.
- Môi trường đa người dùng (Multi-Tenant Environments): Nhiều cụm Kubernetes hỗ trợ nhiều ứng dụng hoặc thậm chí toàn bộ đội nhóm, nghĩa là các khối công việc từ các nhóm khác nhau có thể chạy trên cùng một node. Việc xác định ứng dụng nào tiêu thụ nhiều tài nguyên hoặc gây ra vấn đề có thể là một thách thức.
- Hệ thống phân tán (Distributed Systems): Kubernetes phân phối khối lượng công việc trên nhiều node trong cụm. Điều này tạo ra sự phức tạp trong việc theo dõi yêu cầu và phản hồi giữa các dịch vụ, đặc biệt khi xảy ra sự cố.
- Dữ liệu khổng lồ (Scalability and High Cardinality Metrics): Kubernetes tạo ra lượng lớn dữ liệu, từ việc sử dụng CPU và bộ nhớ đến nhật ký và lưu lượng mạng. Không phải tất cả các chỉ số đều quan trọng như nhau, vì vậy cần lọc bớt nhiễu và tập trung vào dữ liệu có thể hành động.
- Bảo mật và tuân thủ (Security and Compliance): Giám sát Kubernetes đòi hỏi phải xử lý dữ liệu nhạy cảm, làm gia tăng các mối quan tâm về bảo mật và tuân thủ.
Các khái niệm chính trong giám sát Kubernetes
1. Khả năng quan sát: Hiểu rõ cụm của bạn
Khả năng quan sát tập trung vào bốn trụ cột chính:
- Sự kiện (Events): Các sự kiện quan trọng trong cụm Kubernetes, như thao tác mở rộng, lỗi pod, hoặc hoàn thành công việc. Giám sát các sự kiện này giúp hiểu vòng đời của ứng dụng và tài nguyên.
- Nhật ký (Logs): Theo dõi đầu ra của ứng dụng và các thành phần hệ thống chạy trong pod. Phân tích nhật ký để khắc phục sự cố, cải thiện khả năng hiển thị và xác định xu hướng.
- Truy vết (Traces): Theo dõi luồng của yêu cầu qua các dịch vụ trong cụm, đặc biệt hữu ích trong kiến trúc microservices khi một yêu cầu duy nhất có thể đi qua nhiều dịch vụ trước khi phản hồi.
- Chỉ số (Metrics): Dữ liệu định lượng đo lường hiệu suất hệ thống, chẳng hạn như sử dụng CPU, bộ nhớ, lưu lượng mạng và độ trễ yêu cầu.
2. Giám sát: Biến dữ liệu thành thông tin có thể hành động
Giám sát liên quan đến phân tích dữ liệu thô để thu được thông tin chi tiết. Các lĩnh vực cốt lõi trong giám sát Kubernetes bao gồm:
- Sử dụng tài nguyên: Theo dõi CPU, bộ nhớ và dung lượng đĩa của pod, node và cụm.
- Sức khỏe dịch vụ: Theo dõi thời gian phục vụ yêu cầu (độ trễ), lưu lượng yêu cầu và tỷ lệ lỗi để phát hiện sớm các vấn đề.
- Độ bão hòa: Hiểu mức độ “đầy” của hệ thống — liệu nó có gần đến giới hạn về CPU, bộ nhớ hay băng thông mạng hay không.
3. Cảnh báo: Thông báo khi có sự cố xảy ra
Cảnh báo là một thành phần quan trọng trong giám sát. Bằng cách đặt các ngưỡng trên các chỉ số chính, bạn có thể nhận thông báo khi có điều gì đó bất thường.
Các hướng dẫn cho cảnh báo hiệu quả:
- Chỉ cảnh báo về các vấn đề ảnh hưởng đến người dùng.
- Chỉ cảnh báo về những điều có thể hành động được.
- Chỉ cảnh báo khi cần sự can thiệp của con người. Nếu có thể tự động hóa, hãy làm điều đó.
Phân biệt giữa yếu tố quan trọng và bổ sung trong giám sát
Giám sát quan trọng:
- Node Health: Giám sát CPU, bộ nhớ và dung lượng đĩa của node cụm.
- Pod Status: Theo dõi trạng thái pod, bao gồm pod đang chờ, đang chạy, và thất bại.
- Container Resource Utilization: Giám sát CPU và bộ nhớ của từng container.
- Application Performance: Theo dõi thời gian phản hồi, tỷ lệ lỗi và lưu lượng của ứng dụng.
- Network Performance: Giám sát độ trễ mạng, thông lượng và lỗi.
- Persistent Volume Status: Theo dõi khả dụng và hiệu suất của bộ nhớ.
Giám sát bổ sung:
- Chỉ số ứng dụng chi tiết: Các chỉ số cụ thể về chức năng của ứng dụng.
- Historical Data Analysis: Phân tích xu hướng dài hạn để lập kế hoạch năng lực.
- User Experience Metrics: Giám sát trải nghiệm và mức độ hài lòng của người dùng cuối.
- Phân tích chi phí: Theo dõi chi phí tài nguyên và cơ hội tối ưu hóa.
Các phương pháp tốt nhất để giám sát Kubernetes
- Phân đoạn namespace: Tổ chức cụm thành các đơn vị logic dựa trên đội nhóm, ứng dụng hoặc môi trường (ví dụ: production vs. staging).
- Gắn nhãn tài nguyên: Sử dụng nhãn để lọc chỉ số, tổng hợp nhật ký và thậm chí theo dõi chi phí.
- Tập trung vào “Bốn tín hiệu vàng” (The Four Golden Signals):
- Độ trễ: Thời gian phản hồi yêu cầu.
- Lưu lượng: Mức độ sử dụng hệ thống.
- Tỷ lệ lỗi: Số lượng yêu cầu thất bại.
- Độ bão hòa: Mức độ gần đạt đến giới hạn của hệ thống.
- Tích hợp giám sát vào CI/CD: Phát hiện sớm các vấn đề trong quá trình phát triển hoặc triển khai.
- Tự động hóa cảnh báo: Thiết lập cảnh báo cho các vấn đề quan trọng, đảm bảo chúng có thể hành động và phù hợp để tránh mệt mỏi vì cảnh báo.
- SLOs và SLAs: Định nghĩa và giám sát các mục tiêu cấp dịch vụ (SLOs) và thỏa thuận cấp dịch vụ (SLAs) để đảm bảo dịch vụ đáp ứng các mục tiêu hiệu suất và tính sẵn sàng.
Kết luận
Giám sát không phải là một nhiệm vụ thực hiện một lần mà là một quá trình liên tục phát triển cùng với cơ sở hạ tầng và ứng dụng của bạn. Bằng cách áp dụng chiến lược giám sát toàn diện bao gồm observability, real-time metrics, và intelligent alerting, bạn có thể đảm bảo độ tin cậy, bảo mật và hiệu quả cho các môi trường Kubernetes của mình.


