Index đóng vai trò quan trọng trong việc tối ưu hiệu suất cơ sở dữ liệu, đặc biệt khi xử lý khối lượng dữ liệu lớn. PostgreSQL, một hệ quản trị cơ sở dữ liệu mã nguồn mở, hỗ trợ nhiều loại index khác nhau, bao gồm cả index clustered và non-clustered.
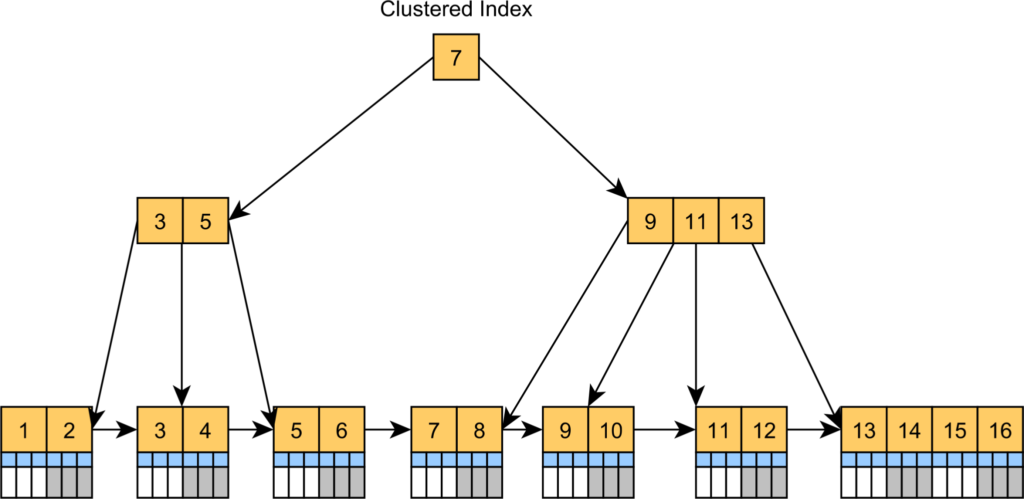
Index Clustered
PostgreSQL không có khái niệm “index clustered” một cách tường minh như trong các hệ quản trị cơ sở dữ liệu khác như SQL Server. Tuy nhiên, ta có thể đạt được hiệu quả tương tự bằng cách sử dụng lệnh CLUSTER. Một index clustered sắp xếp lại dữ liệu của bảng để phù hợp với index, tăng cường hiệu suất đọc cho các truy vấn tận dụng khả năng truy cập tuần tự.
Đặc điểm chính:
- Sắp xếp lại vật lý: Dữ liệu bảng được lưu trữ vật lý theo thứ tự của index.
- Chỉ một index clustered: Mỗi bảng chỉ có thể có một index clustered do chỉ có thể sắp xếp vật lý bảng theo một cách duy nhất.
- Hiệu quả: Có lợi cho các truy vấn phạm vi và truy cập dữ liệu tuần tự.
Index Non-Clustered
Đây là loại index mặc định trong PostgreSQL. Index non-clustered tạo ra một cấu trúc riêng biệt chứa các giá trị cột được đánh index và con trỏ tới các hàng dữ liệu thực tế, mà không làm thay đổi thứ tự vật lý của bảng.
Đặc điểm chính:
- Cấu trúc riêng biệt: Index được lưu trữ tách biệt khỏi dữ liệu bảng.
- Nhiều index non-clustered: Một bảng có thể có nhiều index non-clustered.
- Hiệu quả: Lý tưởng cho các thao tác tra cứu, tìm kiếm và join trên các cột cụ thể.
Ví dụ minh họa:
- Create table:
CREATE TABLE employees (
emp_id SERIAL PRIMARY KEY,
department VARCHAR(50),
hire_date DATE,
salary NUMERIC(10,2)
);
- Insert test data:
INSERT INTO employees (department, hire_date, salary)
SELECT
CASE
WHEN RANDOM() < 0.3 THEN 'Engineering'
WHEN RANDOM() < 0.6 THEN 'Marketing'
ELSE 'Sales'
END,
CURRENT_DATE - ((RANDOM() * 365 * 10)::INT),
(RANDOM() * 50000 + 30000)::NUMERIC(10,2)
FROM generate_series(1, 1000); - Create Non-cluster Index:
CREATE INDEX idx_department ON employees (department);- Create Cluster Index:
CREATE INDEX idx_hire_date ON employees (hire_date);
CLUSTER employees USING idx_hire_date;Bảng employees được sắp xếp lại theo hire_date, cải thiện các truy vấn truy vấn tuần tự theo thứ tự ngày hire_date.
Hiệu quả:
- Index Clustered: Hiệu suất tăng đáng kể đối với các truy vấn tuần tự.
- Index Non-Clustered: Nhanh hơn trong việc tra cứu, tìm kiếm và join trên các cột được đánh index.
Hiểu và sử dụng index là rất quan trọng để tối ưu hóa cơ sở dữ liệu. Mặc dù PostgreSQL không có index clustered nguyên bản, nhưng lệnh CLUSTER có thể mô phỏng lại. Bằng cách sử dụng hiệu quả cả index clustered và non-clustered, bạn có thể đảm bảo cơ sở dữ liệu PostgreSQL hoạt động tối ưu.
Các loại Index khác trong PostgreSQL
Ngoài index clustered và non-clustered, PostgreSQL còn cung cấp một loạt các loại index khác để tối ưu hóa hiệu suất truy vấn:
- Partial Indexes: Index này được xây dựng trên một tập hợp con các hàng trong bảng dựa trên một điều kiện cụ thể. Index một phần có thể tiết kiệm dung lượng và cải thiện hiệu suất cho các truy vấn thường xuyên lọc theo điều kiện đó.
- Unique Indexes: Đảm bảo tính duy nhất của các giá trị trong một cột hoặc một tập hợp các cột, giúp duy trì tính toàn vẹn dữ liệu.
Lựa chọn loại index phù hợp
Việc lựa chọn loại index phù hợp đòi hỏi phải xem xét kỹ lưỡng các đặc điểm dữ liệu của bạn. Bằng cách đánh index phù hợp, bạn có thể cải thiện đáng kể hiệu suất của cơ sở dữ liệu PostgreSQL của mình. Lưu ý rằng index không phải là giải pháp phù hợp cho mọi trường hợp, hãy phân tích kỹ lưỡng là chìa khóa để tối đa hóa lợi ích của chúng.

