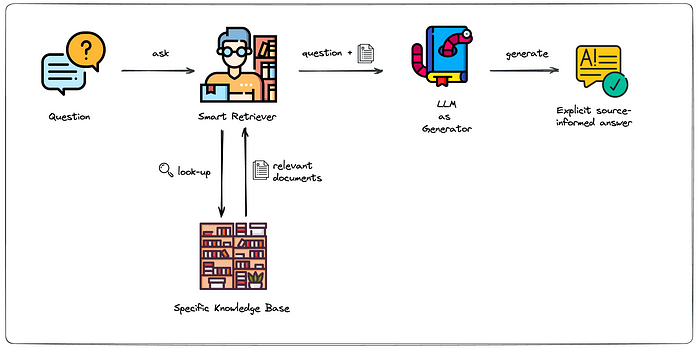
Trong thế giới trí tuệ nhân tạo đang phát triển nhanh chóng, các mô hình ngôn ngữ đã trải qua một sự tiến hóa đáng kinh ngạc. Từ những hệ thống đơn giản dựa trên quy tắc đến các mạng nơ-ron phức tạp mà chúng ta thấy ngày nay, mỗi bước tiến đều mở rộng đáng kể khả năng xử lý ngôn ngữ của AI. Một bước đột phá quan trọng trong hành trình này là sự ra đời của Retrieval-Augmented Generation (RAG).
RAG đại diện cho sự kết hợp giữa các mô hình ngôn ngữ truyền thống với một cải tiến sáng tạo: tích hợp việc truy xuất thông tin trực tiếp vào quá trình tạo văn bản. Hãy hình dung nó như một AI có khả năng tra cứu thông tin trong một thư viện văn bản trước khi phản hồi, giúp nó trở nên hiểu biết hơn và nhận thức ngữ cảnh tốt hơn. Khả năng này không chỉ là một cải tiến nhỏ—nó là một thay đổi mang tính cách mạng. Nó cho phép các mô hình tạo ra các phản hồi không chỉ chính xác mà còn được hỗ trợ sâu sắc bởi thông tin thực tế và liên quan.
RAG là gì?
Trong các mô hình ngôn ngữ truyền thống, phản hồi được tạo ra dựa trên các mẫu và thông tin đã học trong quá trình huấn luyện. Tuy nhiên, các mô hình này bị giới hạn bởi dữ liệu mà chúng đã được huấn luyện, thường dẫn đến các phản hồi thiếu chiều sâu hoặc kiến thức cụ thể. RAG giải quyết hạn chế này bằng cách lấy thông tin bên ngoài khi cần trong quá trình tạo văn bản.
Cách thức hoạt động như sau: khi có một truy vấn, hệ thống RAG trước tiên sẽ truy xuất thông tin liên quan từ một tập dữ liệu lớn hoặc cơ sở tri thức. Sau đó, thông tin này được sử dụng để hướng dẫn và cải thiện quá trình tạo phản hồi.
Kiến trúc của RAG
RAG là một hệ thống tinh vi được thiết kế để nâng cao khả năng của các mô hình ngôn ngữ lớn bằng cách kết hợp chúng với các cơ chế truy xuất mạnh mẽ. Nó bao gồm hai thành phần chính: Retriever (bộ truy xuất) và Generator (bộ tạo văn bản).
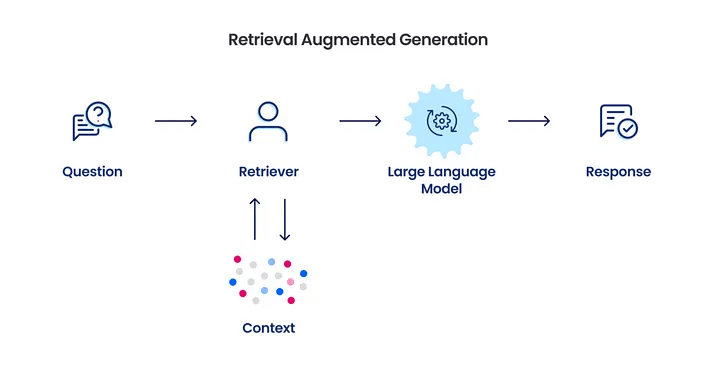
Thành phần Retriever (Bộ truy xuất)
- Chức năng: Nhiệm vụ của retriever là tìm kiếm các tài liệu hoặc thông tin liên quan có thể giúp trả lời truy vấn. Nó nhận truy vấn đầu vào và tìm kiếm trong cơ sở dữ liệu để truy xuất thông tin hữu ích.
- Các loại Retriever:
- Dense Retriever: Sử dụng các phương pháp dựa trên mạng nơ-ron để tạo ra các vector biểu diễn văn bản. Chúng hoạt động tốt khi ý nghĩa tổng thể quan trọng hơn từ ngữ cụ thể, vì các vector này nắm bắt được sự tương đồng ngữ nghĩa.
- Sparse Retriever: Dựa trên các kỹ thuật khớp từ như TF-IDF hoặc BM25. Chúng hiệu quả trong việc tìm kiếm tài liệu có khớp từ khóa chính xác, đặc biệt hữu ích khi truy vấn chứa các thuật ngữ độc đáo hoặc hiếm.
Thành phần Generator (Bộ tạo văn bản)
- Chức năng: Generator là mô hình ngôn ngữ tạo ra phản hồi cuối cùng. Nó nhận truy vấn và ngữ cảnh từ retriever để tạo ra một phản hồi mạch lạc và liên quan.
- Tương tác với Retriever: Generator không hoạt động độc lập; nó sử dụng ngữ cảnh do retriever cung cấp để đảm bảo phản hồi không chỉ hợp lý mà còn giàu thông tin và chính xác.
Quy trình hoạt động của RAG
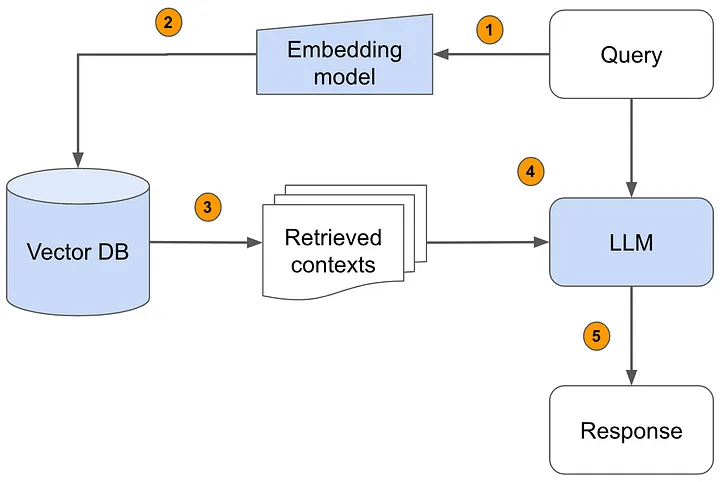
- Xử lý truy vấn: Bắt đầu với một truy vấn—có thể là câu hỏi, lời nhắc hoặc bất kỳ đầu vào nào cần phản hồi.
- Mô hình Embedding: Truy vấn được chuyển qua một mô hình embedding để chuyển đổi thành vector số có thể xử lý.
- Truy xuất từ cơ sở dữ liệu vector: Sử dụng vector truy vấn để tìm kiếm trong cơ sở dữ liệu vector, truy xuất các ngữ cảnh liên quan nhất.
- Ngữ cảnh được truy xuất: Các ngữ cảnh này được chuyển đến mô hình ngôn ngữ lớn (LLM).
- LLM tạo phản hồi: LLM sử dụng cả truy vấn và ngữ cảnh để tạo ra phản hồi toàn diện và liên quan.
- Phản hồi cuối cùng: Phản hồi được cung cấp, được tăng cường bởi dữ liệu bên ngoài, làm cho nó chính xác và chi tiết hơn.
Lựa chọn Retriever: Việc chọn giữa dense và sparse retriever phụ thuộc vào tính chất của cơ sở dữ liệu và loại truy vấn. Dense retriever tốn kém về tính toán nhưng nắm bắt được mối quan hệ ngữ nghĩa sâu sắc, trong khi sparse retriever nhanh hơn và tốt cho khớp thuật ngữ cụ thể.
- Mô hình kết hợp: Một số hệ thống RAG sử dụng retriever kết hợp cả hai kỹ thuật để cân bằng ưu và nhược điểm của mỗi phương pháp.
Ứng dụng của RAG
Nâng cao Chatbot và trợ lý hội thoại
- Hỗ trợ khách hàng: Chatbot sử dụng RAG có thể truy xuất thông tin sản phẩm, FAQ và tài liệu hỗ trợ để cung cấp phản hồi chính xác cho khách hàng.
- Trợ lý cá nhân: Trợ lý ảo sử dụng RAG để lấy dữ liệu thời gian thực như thời tiết hoặc tin tức, làm cho tương tác trở nên hữu ích hơn.
Cải thiện độ chính xác trong tạo nội dung tự động
- Sáng tạo nội dung: Công cụ AI báo chí sử dụng RAG để lấy số liệu và sự kiện, tạo ra bài viết giàu thông tin và ít cần chỉnh sửa.
- Viết quảng cáo: Bot tiếp thị sử dụng RAG để tạo mô tả sản phẩm và nội dung quảng cáo chính xác và sáng tạo.
Ứng dụng trong hệ thống hỏi đáp
- Nền tảng giáo dục: RAG cung cấp cho học sinh giải thích chi tiết và ngữ cảnh bổ sung bằng cách truy xuất thông tin từ cơ sở dữ liệu giáo dục.
- Nghiên cứu: Hệ thống AI giúp nhà nghiên cứu tìm câu trả lời bằng cách tham khảo tài liệu học thuật và tóm tắt các nghiên cứu liên quan.
Lợi ích trong các lĩnh vực khác
- Chăm sóc sức khỏe: Hỗ trợ chuyên gia y tế bằng cách truy xuất thông tin từ tạp chí y khoa và hồ sơ bệnh nhân.
- Dịch vụ khách hàng: Cung cấp lời khuyên cá nhân hóa bằng cách truy xuất chính sách công ty và lịch sử khách hàng.
- Giáo dục: Giáo viên sử dụng RAG để tạo kế hoạch bài giảng và tài liệu học tập tùy chỉnh, cung cấp nhiều góc nhìn cho học sinh.
Thách thức trong triển khai RAG
- Độ phức tạp: Kết hợp truy xuất và tạo văn bản làm tăng độ phức tạp, khó phát triển và duy trì.
- Khả năng mở rộng: Quản lý và tìm kiếm trong cơ sở dữ liệu lớn gặp khó khăn khi dữ liệu tăng lên.
- Độ trễ: Quá trình truy xuất có thể gây chậm trễ, ảnh hưởng đến thời gian phản hồi, quan trọng trong tương tác thời gian thực.
- Đồng bộ hóa: Cần cơ chế cập nhật cơ sở dữ liệu truy xuất mà không làm giảm hiệu suất.
Hạn chế của mô hình RAG hiện tại
- Giới hạn ngữ cảnh: Khó khăn khi ngữ cảnh cần thiết vượt quá giới hạn đầu vào của mô hình.
- Lỗi truy xuất: Chất lượng phản hồi phụ thuộc vào thông tin truy xuất; truy xuất sai dẫn đến phản hồi kém.
- Thiên kiến: Có thể vô tình lan truyền và khuếch đại thiên kiến từ dữ liệu nguồn.
Cải tiến tiềm năng
- Tích hợp tốt hơn: Kết hợp mượt mà giữa retriever và generator để xử lý truy vấn phức tạp.
- Thuật toán truy xuất nâng cao: Cải thiện chất lượng truy xuất ngữ cảnh, nâng cao chất lượng nội dung tạo ra.
- Học tập thích ứng: Cho phép mô hình học từ thành công và thất bại trong truy xuất để tinh chỉnh hệ thống theo thời gian.
Sự phụ thuộc vào dữ liệu và nguồn truy xuất
- Chất lượng dữ liệu: Hiệu quả của RAG phụ thuộc vào chất lượng dữ liệu trong cơ sở dữ liệu truy xuất.
- Độ tin cậy của nguồn: Cần đảm bảo nguồn thông tin đáng tin cậy, đặc biệt trong y tế và giáo dục.
- Quyền riêng tư và an ninh: Xử lý thông tin nhạy cảm đòi hỏi chú ý đến quyền riêng tư và an ninh dữ liệu.
Xu hướng mới và nghiên cứu đang tiến hành
- Truy xuất đa phương thức: Mở rộng RAG để truy xuất hình ảnh và video, tạo phản hồi đa phương tiện.
- Học tập liên tục: Phát triển hệ thống RAG học từ mỗi tương tác mà không cần huấn luyện lại.
- Truy xuất tương tác: Cho phép generator yêu cầu thêm thông tin hoặc làm rõ, giống như trong hội thoại của con người.
- Thích ứng theo lĩnh vực: Tùy chỉnh RAG cho các lĩnh vực cụ thể như pháp lý hoặc y tế để cải thiện độ chính xác.
Cải tiến tương lai
- Cá nhân hóa: Tích hợp hồ sơ người dùng và lịch sử tương tác để cá nhân hóa phản hồi.
- Kiến thức nền tảng: Sử dụng cơ sở kiến thức ngoài để đảm bảo phản hồi dựa trên sự thật có thể xác minh.
- Lập chỉ mục hiệu quả: Áp dụng cấu trúc dữ liệu và thuật toán hiệu quả để tăng tốc truy xuất và giảm chi phí tính toán.

