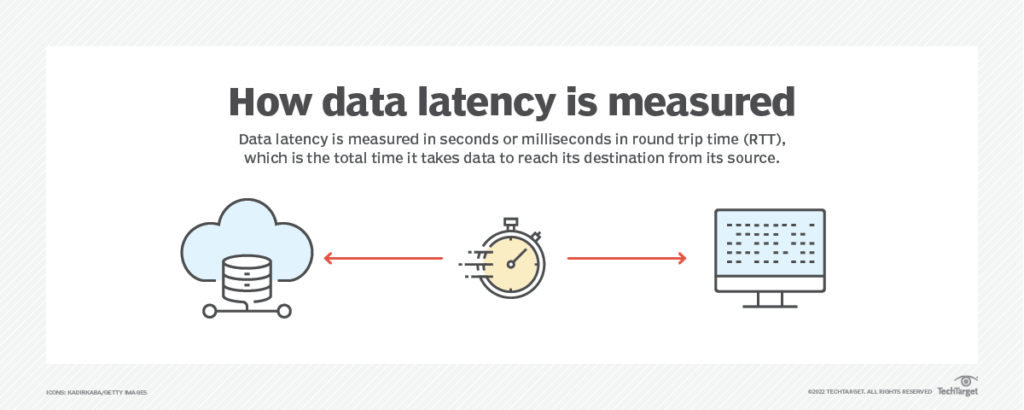
Trong 10 năm trở lại đây, Amazon phát hiện ra rằng cứ 100 mili giây độ trễ sẽ khiến họ mất đi 1% doanh thu.
Đó là một con số đáng kinh ngạc 5,7 tỷ USD theo thời giá ngày nay. Đối với các hệ thống hướng tới người dùng quy mô cao, độ trễ cao là một tổn thất lớn về doanh thu.
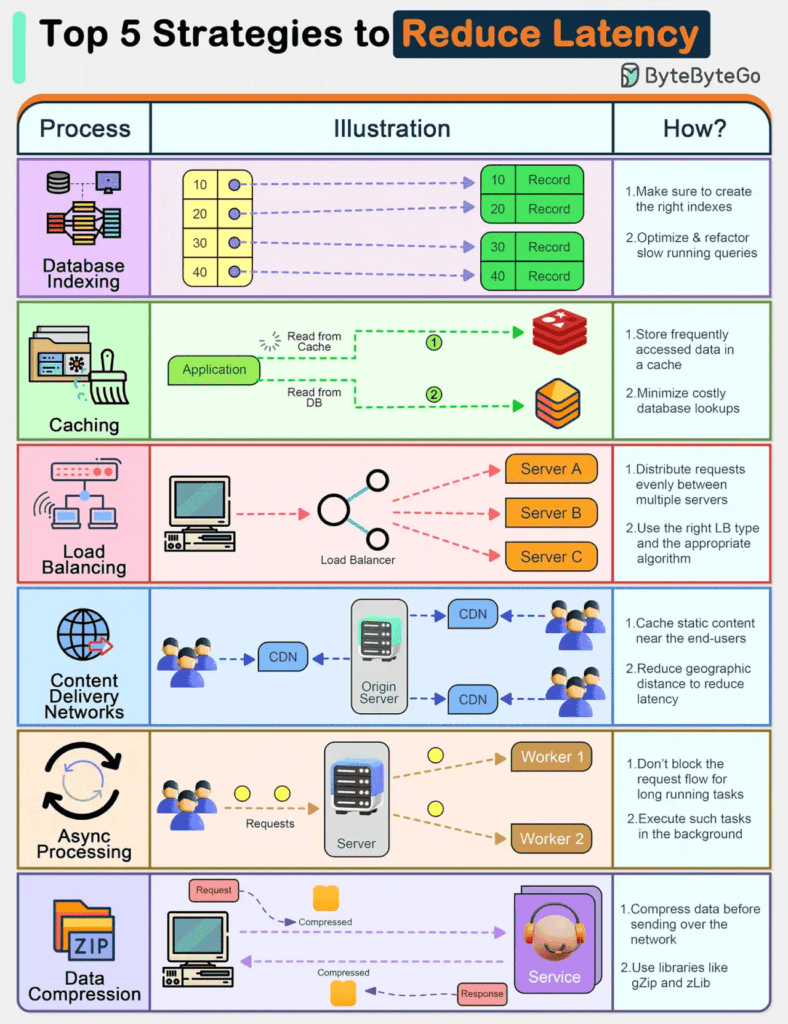
Vì vậy, trong bài viết này, chúng ta hãy cũng tìm hiểu những phương pháp để giảm thiểu độ trễ nhé.
Database indexing
1. Overview
Database indexing là một bước quan trọng trong việc tối ưu hóa các truy vấn cơ sở dữ liệu của bạn. Một chỉ mục trong cơ sở dữ liệu hoạt động tương tự như một chỉ mục trong sách; nó cho phép cơ sở dữ liệu tìm và truy xuất dữ liệu cụ thể nhanh hơn.
- Cải Thiện Tốc Độ Truy Vấn: Index giảm lượng dữ liệu mà cơ sở dữ liệu phải quét, điều này đáng kể tăng tốc độ các thao tác đọc.
- Tối Ưu Hóa Các Hoạt Động Tìm Kiếm: Đặc biệt hữu ích cho các tập dữ liệu lớn, lập index có thể cải thiện hiệu quả tìm kiếm và giảm thời gian phản hồi.
Khi thực hiện lập chỉ mục cơ sở dữ liệu, điều quan trọng là xem xét các loại truy vấn mà ứng dụng của bạn thực hiện thường xuyên nhất và tạo các chỉ mục có lợi cho những truy vấn đó. Tuy nhiên, hãy nhớ rằng trong khi các chỉ mục tăng tốc độ thao tác đọc, chúng có thể làm chậm các thao tác ghi, vì vậy cần có sự cân bằng hợp lý.
2. Cấu trúc của một Index:
- Cột Search Key: chứa bản sao các giá trị của cột được tạo Index
- Cột Data Reference: chứa con trỏ trỏ đến địa chỉ của bản ghi có giá trị cột index tương ứng

3. Một số loại index phổ biến
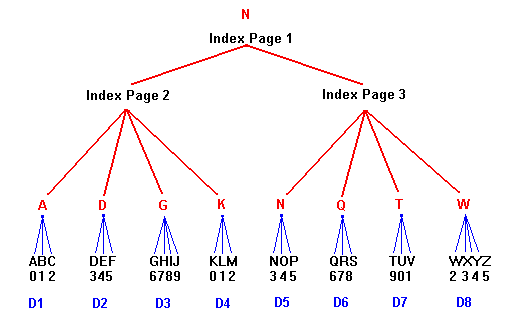
- B-Tree
- Là kiểu dữ liệu phổ biến nhất cho Index
- Dữ liệu index trong B-Tree được tổ chức và lưu trữ theo dạng tree, tức là có root, branch, leaf.
- Ý tưởng chung của B-Tree là lưu trữ các giá trị được sắp xếp, mỗi leaf node có độ cao bằng nhau tính từ gốc. B-Tree có thể tăng tốc truy vấn vì storage engine không cần tìm toàn bộ bản ghi của bảng. Thay vào đó, nó sẽ tìm từ node root, root sẽ chứa con trỏ tới node con, storeage engine sẽ dựa vào con trỏ đó. Nó tìm đúng con trỏ bằng cách xét giá trị của node pages, nơi chứa khoảng giá trị của các node con. Cuối cùng, storage engine chỉ ra rằng giá trị không tồn tại hoặc tìm được giá trị ở leaf node.
- B-Tree index được sử dụng trong các biểu thức so sánh dạng: =, >, >=, <, <=, BETWEEN và LIKE
- B-Tree index được sử dụng cho những column trong bảng khi muốn tìm kiếm 1 giá trị nằm trong khoảng nào đó
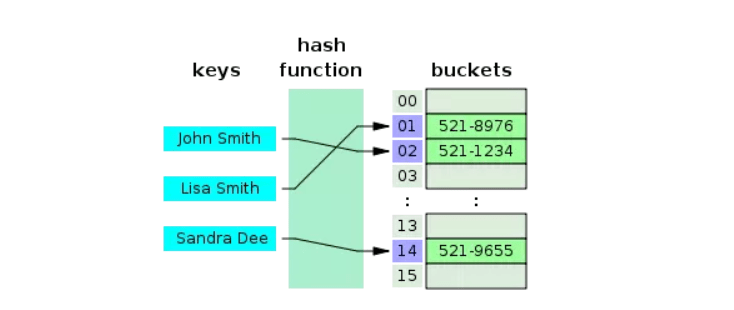
- Hash-Index
- Dữ liệu index được tổ chức theo dạng Key – Value được liên kết với nhau.
- Khác với B-Tree, thì Hash index chỉ nên sử dụng trong các biểu thức toán tử là = và <>. Không sử dụng cho toán từ tìm kiếm 1 khoảng giá trị như > hay <
- Không thể tối ưu hóa toán tử ORDER BY bằng việc sử dụng Hash index bởi vì nó không thể tìm kiếm được phần từ tiếp theo trong Order.
- Toàn bộ nội dung của Key được sử dụng để tìm kiếm giá trị records, khác với B-Tree một phần của node cũng có thể được sử dụng để tìm kiếm.
- Hash có tốc độ nhanh hơn kiểu Btree.
4. Nhược điểm của Database Indexing
- Cần nhiều không gian lưu trữ hơn để chứa cấu trúc dữ liệu chỉ mục, điều này có thể làm tăng tổng kích thước của cơ sở dữ liệu.
- Tăng chi phí bảo trì cơ sở dữ liệu: các index phải được duy trì khi dữ liệu được thêm, hủy hoặc sửa đổi trong bảng, điều này có thể làm tăng chi phí bảo trì cơ sở dữ liệu.
- Indexing có thể làm giảm hiệu suất chèn và cập nhật do cấu trúc dữ liệu chỉ mục phải được cập nhật mỗi khi dữ liệu được sửa đổi.
5. Tài Liệu tham khảo
6. Bài viết liên quan
https://ant.ncc.asia/p-1-shell-scripting-quick-beginners-guide/


