Chào các bạn đọc thân yêu, chúng ta đã đi qua 3 phần trong series “Nhập môn Machine Learning”. Trong phần này, chúng ta sẽ tìm hiểu về một thuật toán quan trọng trong Machine Learning, đó là K-Means.
1. Giới thiệu
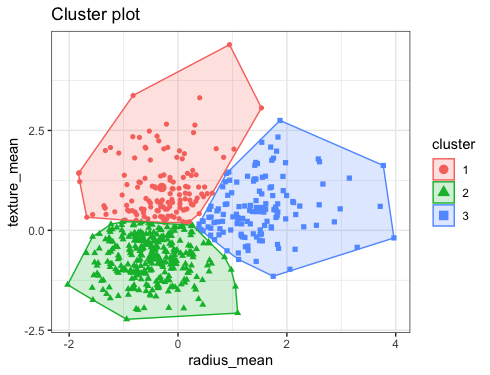
K-Means là một thuật toán unsupervised learning, tức là nó không cần các nhãn đúng cho dữ liệu đầu vào. Thuật toán này được sử dụng phổ biến trong việc phân cụm dữ liệu, nghĩa là chia tập dữ liệu thành các nhóm (clusters) dựa trên sự tương đồng giữa các điểm dữ liệu.
Ví dụ: Một công ty muốn tạo ra những chính sách ưu đãi cho những nhóm khách hàng khác nhau dựa trên sự tương tác giữa mỗi khách hàng với công ty đó (số năm là khách hàng; số tiền khách hàng đã chi trả cho công ty; độ tuổi; giới tính; thành phố; nghề nghiệp; …).
2. Phân tích toán học
Một số ký hiệu toán học
- N: Số lượng điểm dữ liệu.
- M: Số lượng clusters mong muốn.
- X: Ma trận dữ liệu đầu vào có kích thước (N, d), trong đó d là số chiều của mỗi điểm dữ liệu.
- Y: Ma trận cluster assignments có kích thước (N, 1), đánh dấu mỗi điểm dữ liệu thuộc về cluster nào.
Hàm mất mát và bài toán tối ưu
K-Means cố gắng tối thiểu hóa hàm mất mát sau đây:

Thuật toán tối ưu hàm mất mát
Thuật toán K-Means hoạt động theo các bước sau:
- Cố định M, tìm Y: Gán mỗi điểm dữ liệu vào cluster có centroid gần nhất.
- Cố định Y, tìm M: Cập nhật centroid của mỗi cluster là trung bình của các điểm dữ liệu trong cluster đó.
- Lặp lại bước 1 và 2 cho đến khi không có sự thay đổi trong phân cụm hoặc đạt đến số lần lặp tối đa.
Tóm tắt thuật toán
Đầu vào: Dữ liệu X và số lượng cluster cần tìm K.
Đầu ra: Các center M và label vector cho từng điểm dữ liệu Y.
- Chọn K điểm bất kỳ làm các center ban đầu.
- Phân mỗi điểm dữ liệu vào cluster có center gần nó nhất.
- Nếu việc gán dữ liệu vào từng cluster ở bước 2 không thay đổi so với vòng lặp trước nó thì ta dừng thuật toán.
- Cập nhật center cho từng cluster bằng cách lấy trung bình cộng của tất các các điểm dữ liệu đã được gán vào cluster đó sau bước 2.
- Quay lại bước 2.
3. Ví dụ trên Python
Giới thiệu bài toán
Chúng ta sẽ bắt đầu với một ví dụ cụ thể. Giả sử chúng ta có tập dữ liệu chứa thông tin về chiều cao và cân nặng của một nhóm người.
Hiển thị dữ liệu trên đồ thị
Trước hết, chúng ta sẽ hiển thị dữ liệu trên một biểu đồ để xem liệu có bao nhiêu cụm dữ liệu mà chúng ta nên chia.
import matplotlib.pyplot as plt
# Dữ liệu ví dụ: chiều cao và cân nặng của các người
height = [155, 160, 162, 165, 170, 175, 180, 185]
weight = [50, 58, 59, 65, 72, 75, 80, 92]
# Hiển thị dữ liệu trên đồ thị
plt.scatter(height, weight)
plt.xlabel('Chiều Cao (cm)')
plt.ylabel('Cân Nặng (kg)')
plt.title('Dữ liệu chiều cao và cân nặng của người')
plt.show()
Các hàm số cần thiết cho K-means clustering
Chúng ta sẽ cần viết các hàm để thực hiện K-Means clustering, bao gồm việc cập nhật centroid và gán các điểm dữ liệu vào cluster tương ứng.
import numpy as np
# Hàm tính khoảng cách Euclidean giữa hai điểm
def euclidean_distance(point1, point2):
return np.sqrt(np.sum((point1 - point2) ** 2))
# Hàm gán các điểm dữ liệu vào cluster tương ứng
def assign_clusters(data, centroids):
clusters = []
for point in data:
distances = [euclidean_distance(point, centroid) for centroid in centroids]
cluster = np.argmin(distances)
clusters.append(cluster)
return clusters
# Hàm cập nhật centroids
def update_centroids(data, clusters, k):
new_centroids = []
for cluster in range(k):
cluster_points = [data[i] for i in range(len(data)) if clusters[i] == cluster]
new_centroid = np.mean(cluster_points, axis=0)
new_centroids.append(new_centroid)
return new_centroids
Kết quả tìm được bằng thư viện scikit-learn
Chúng ta cũng có thể sử dụng thư viện scikit-learn để thực hiện K-Means một cách nhanh chóng và tiện lợi.
from sklearn.cluster import KMeans
# Tạo đối tượng KMeans với số lượng clusters cần chia
kmeans = KMeans(n_clusters=2)
# Thực hiện K-Means clustering trên dữ liệu
kmeans.fit(data)
# Lấy thông tin về centroids và các clusters
centroids = kmeans.cluster_centers_
clusters = kmeans.labels_
print("Centroids:")
print(centroids)
print("Clusters:")
print(clusters)
4. Điểm hạn chế
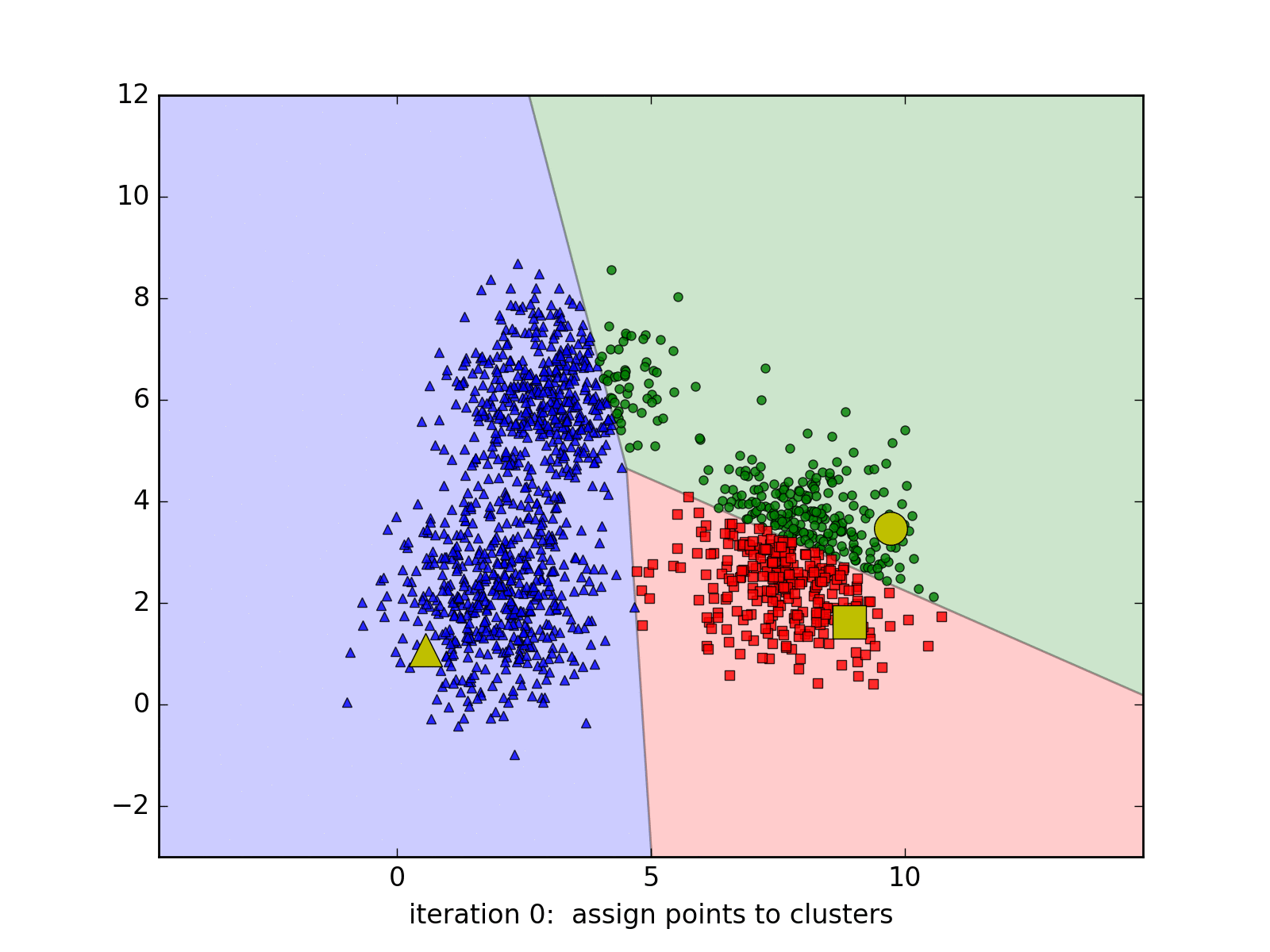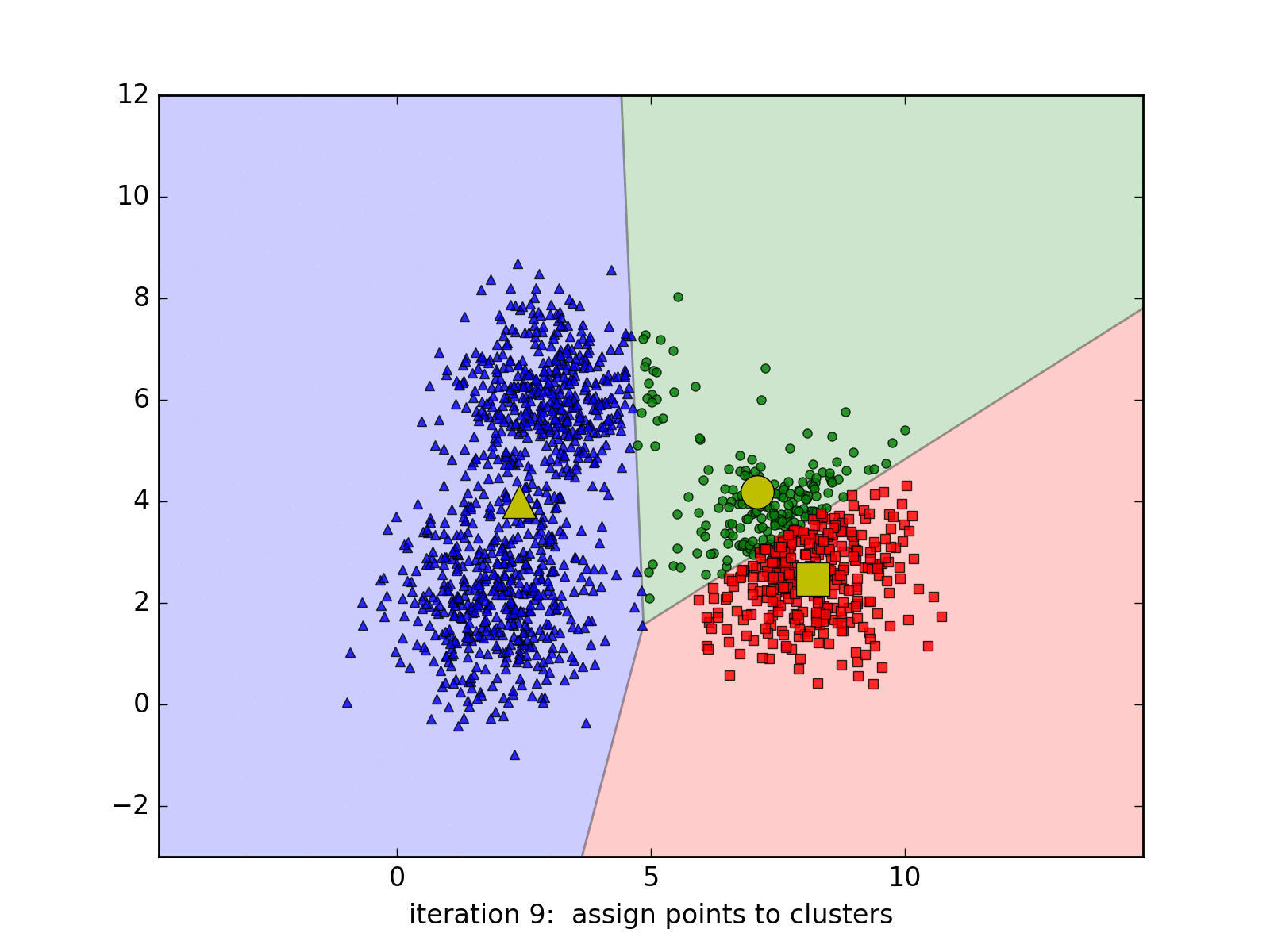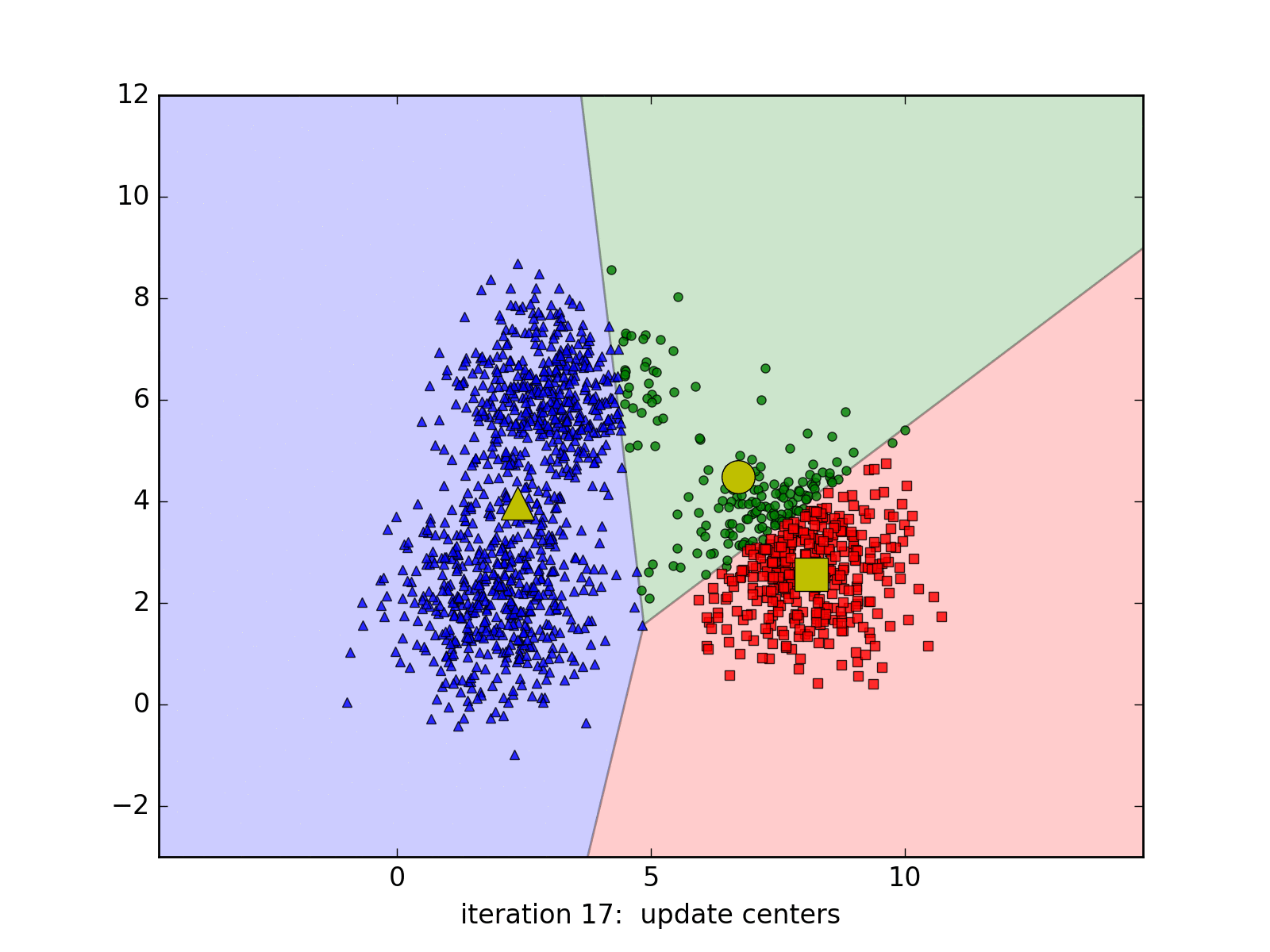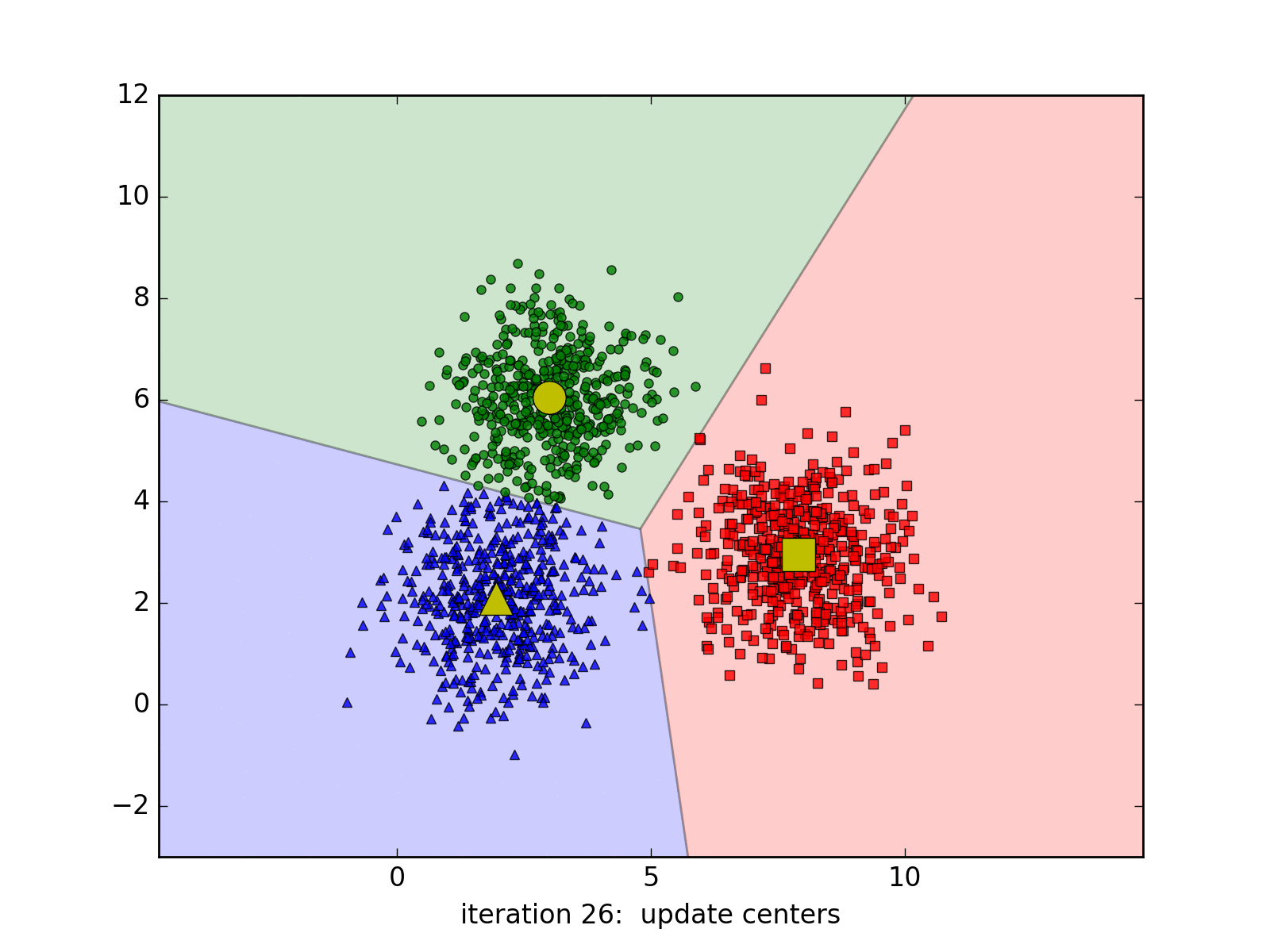
Mặc dù K-Means là một thuật toán mạnh mẽ trong machine learning, nó cũng có một số hạn chế. Ví dụ, nó đòi hỏi bạn phải biết trước số lượng clusters cần chia tập dữ liệu thành. Ngoài ra, nó nhạy cảm với khởi tạo ban đầu của centroids. Tùy vào các center ban đầu mà thuật toán có thể có tốc độ hội tụ rất chậm, ví dụ:
5. Tài liệu tham khảo
Dưới đây là một số tài liệu tham khảo để bạn có thể tìm hiểu thêm về K-Means và Machine Learning:


