Tiếp tục với một số phương pháp xử lý overfitting
Data Augmentation
Chắc hẳn là hầu hết chúng ta đều biết Overfitting là hiện tượng model của chúng ta đang quá khớp với training set, dẫn đến kết quả kém trên dữ liệu kiểm tra hoặc dữ liệu mới. Từ lý thuyết đó, việc làm đa dạng hoá dữ liệu là một trong những yếu tố cực kỳ quan trọng trong quá trình giải quyết overfitting. Data Augmentation là một trong những phương pháp giúp tăng sự đa dạng dữ liệu đó.
Sử dụng phương pháp Data Augmentation, tăng thêm số lượng dữ liệu ta có bằng cách thay đổi một số đặc tính của dữ liệu cũ như xoay, lật, nghiêng hay điều chỉnh lại tỉ lệ của những hình ảnh cũ trong tập data cũ.
Phương pháp này thường được áp dụng cho dữ liệu hình ảnh, âm thanh, hay văn bản, nhằm tạo ra các biến thể của dữ liệu ban đầu, giúp mô hình học được nhiều góc độ và trường hợp khác nhau của dữ liệu, tránh việc mô hình bị phụ thuộc vào một số đặc điểm cố định của dữ liệu huấn luyện.
Một số ví dụ Data Augmentation:
- Thay đổi màu sắc:
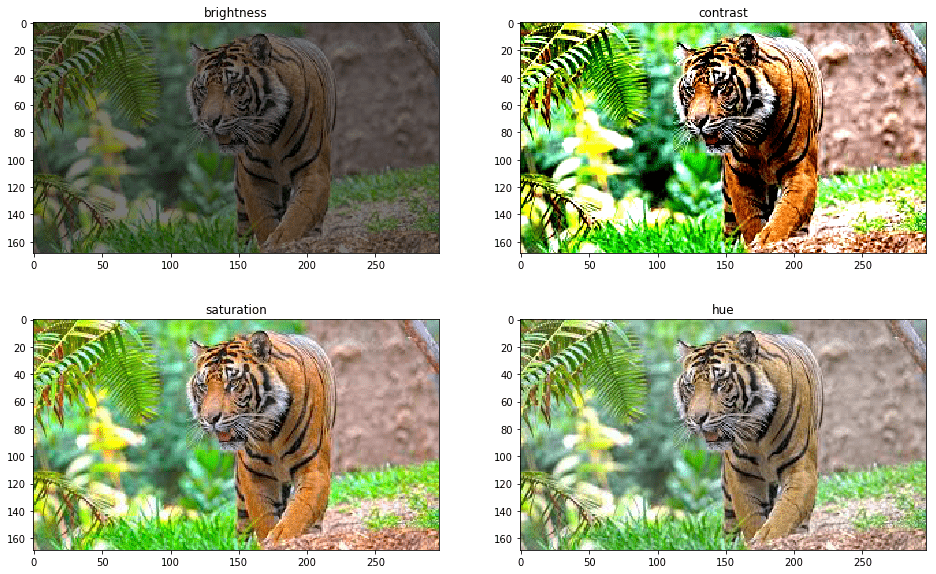
- Thay đổi góc độ (xoay ảnh):

Generative Adverserial Network
Dùng thuật toán GAN (Generative Adverserial Network) – một mô hình học không giám sát dùng để sinh dữ liệu từ nhiễu (noise). GAN gồm hai mạng neural đối nghịch nhau: một mạng sinh (generator) và một mạng phân biệt (discriminator).
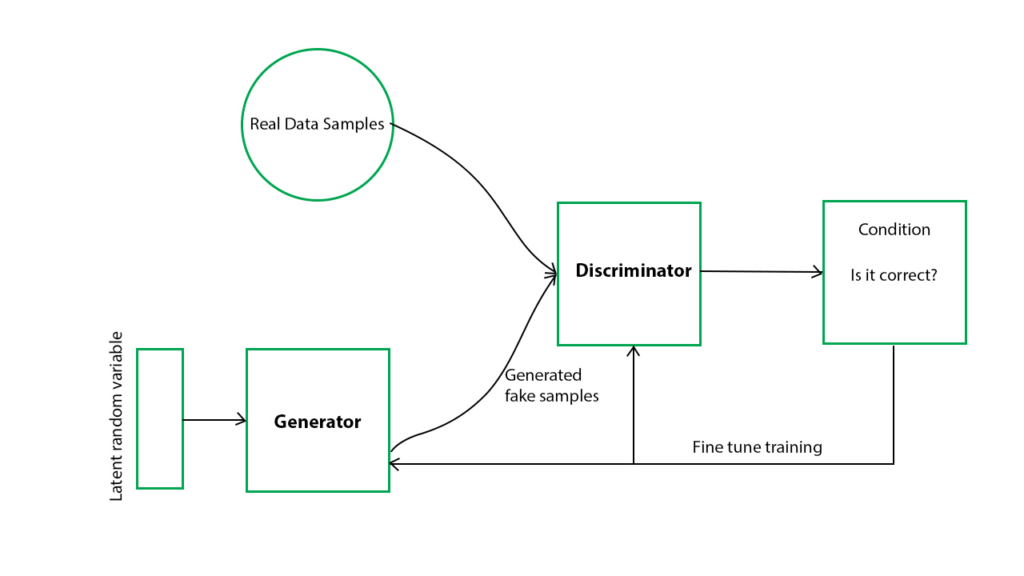
Mạng sinh có nhiệm vụ tạo ra dữ liệu giống với dữ liệu thật từ nhiễu đầu vào, còn mạng phân biệt có nhiệm vụ phân biệt dữ liệu thật và dữ liệu giả. Quá trình huấn luyện GAN là quá trình cân bằng giữa hai mạng, khiến cho mạng sinh có thể tạo ra dữ liệu giống thật đến mức mạng phân biệt không thể phân biệt được.
GAN có thể được sử dụng để tăng cường dữ liệu, bằng cách sử dụng mạng sinh để tạo ra các dữ liệu mới từ nhiễu. GAN có thể tạo ra các dữ liệu rất chân thực và đa dạng, nhưng cũng rất khó huấn luyện và cần nhiều tài nguyên tính toán.
Kết hợp với các phương pháp như Regularization, Dropout, Early stoping
Các phương pháp này đều nhằm mục đích giảm độ phức tạp của mô hình, tránh việc mô hình học quá nhiều chi tiết và nhiễu của dữ liệu huấn luyện.
- Regularization là kỹ thuật thêm vào hàm mất mát (loss function) một số hạng phạt cho trọng số (weight) của mô hình, khiến cho trọng số có giá trị nhỏ hơn, giảm overfitting.
- Dropout là kỹ thuật loại bỏ ngẫu nhiên một số nơ-ron (neuron) trong mạng neural trong quá trình huấn luyện, giúp mô hình không phụ thuộc quá nhiều vào một số nơ-ron cụ thể, tăng khả năng khái quát hóa.
- Early stoping là kỹ thuật dừng quá trình huấn luyện khi độ lỗi (error) trên tập kiểm tra không cải thiện thêm, tránh việc mô hình tiếp tục học những chi tiết không cần thiết của tập huấn luyện.
- Cross-validation, là kỹ thuật chia tập dữ liệu thành K tập con có kích thước bằng nhau, gọi là nhóm, và huấn luyện mô hình trên K-1 nhóm, rồi kiểm tra trên nhóm còn lại. Quá trình này được lặp lại K lần, mỗi lần chọn một nhóm khác nhau làm tập kiểm tra. Kết quả cuối cùng là trung bình của K lần kiểm tra.
Cảm ơn bạn đã đọc
Nguồn tham khảo:
Machine Learning cơ bản (machinelearningcoban.com)
Các phương pháp tránh Overfitting – Regularization, Dropout (viblo.asia)
What is so special about Generative Adversarial Network (GAN) – GeeksforGeeks
What is data augmentation in CNN? – Quora
The Essential Guide to Data Augmentation in Deep Learning (v7labs.com)