Giới thiệu
Mạng nơ-ron nhân tạo là một hệ thống gồm các nơ-ron kết nối với nhau, có khả năng học hỏi và đưa ra quyết định giống như bộ não con người. Mặc dù một perceptron đơn lẻ chỉ có thể thực hiện các nhiệm vụ đơn giản, nhưng khi kết nối nhiều perceptron lại với nhau trong một mạng nơ-ron, chúng ta có thể giải quyết các vấn đề phức tạp hơn, chẳng hạn như nhận dạng hình ảnh.
Sơ bộ về Mạng Nơ-ron nhân tạo
Bộ não của chúng ta đưa ra quyết định với hàng trăm tỷ nơ-ron, có hàng nghìn tỷ kết nối giữa chúng. Chúng ta có thể làm được nhiều điều tuyệt vời với AI nếu kết nối nhiều perceptron lại với nhau để tạo ra một mạng nơ-ron nhân tạo.
Mạng nơ-ron vượt trội hơn các phương pháp khác trong một số nhiệm vụ nhất định như nhận dạng hình ảnh. Bí quyết thành công của chúng nằm ở các lớp ẩn và sự tinh tế về mặt toán học. Đây là lý do tại sao mạng nơ-ron là một trong những công nghệ học máy phổ biến nhất hiện nay.
Không lâu trước đây, một thách thức lớn trong AI là nhận dạng hình ảnh trong thế giới thực, như phân biệt một con chó với một con mèo hay một chiếc xe với một chiếc máy bay hoặc một chiếc thuyền. Mặc dù chúng ta làm điều đó hàng ngày, nhưng thực sự rất khó cho máy tính.
Bộ dữ liệu ImageNet và sự phát triển của mạng Nơ-ron

Không lâu trước đây, một thách thức lớn trong AI là nhận dạng hình ảnh trong thế giới thực, như phân biệt một con chó với một con mèo, và một chiếc xe với một chiếc máy bay hoặc một chiếc thuyền. Mặc dù chúng ta làm điều đó hàng ngày, nhưng thực sự rất khó cho máy tính. Đó là vì máy tính giỏi trong việc so sánh từng chi tiết, như so khớp các số 0 và 1, từng cái một. Máy tính dễ dàng nhận ra rằng các hình ảnh này giống nhau bằng cách so khớp các điểm ảnh. Nhưng trước khi có AI, máy tính không thể nhận ra rằng các hình ảnh này đều là của cùng một con chó, và không có hy vọng nhận ra rằng tất cả các hình ảnh khác nhau này đều là chó. Vì vậy, một giáo sư tên là Fei-Fei Li và một nhóm các nhà nghiên cứu học máy và thị giác máy tính đã muốn giúp cộng đồng nghiên cứu phát triển AI có thể nhận dạng hình ảnh. Bước đầu tiên là tạo ra một bộ dữ liệu công khai khổng lồ gồm các bức ảnh thực tế được gán nhãn. Bằng cách đó, các nhà khoa học máy tính trên khắp thế giới có thể đưa ra và thử nghiệm các thuật toán khác nhau. Họ gọi bộ dữ liệu này là ImageNet. Nó có 3,2 triệu hình ảnh được gán nhãn, được phân loại thành 5.247 danh mục danh từ lồng nhau. Ví dụ, nhãn “chó” được lồng dưới “động vật nuôi,” và “động vật nuôi” được lồng dưới “động vật.” Con người là những người giỏi nhất trong việc gán nhãn dữ liệu một cách đáng tin cậy. Nhưng nếu một người làm tất cả việc gán nhãn này, mất 10 giây cho mỗi nhãn, mà không nghỉ ngơi hay ăn uống, thì sẽ mất hơn một năm! Vì vậy, ImageNet đã sử dụng phương pháp đám đông và tận dụng sức mạnh của Internet để phân chia công việc này cho hàng ngàn người. Khi dữ liệu đã sẵn sàng, các nhà nghiên cứu đã bắt đầu một cuộc thi hàng năm vào năm 2010 để mọi người đóng góp các giải pháp tốt nhất của họ cho việc nhận dạng hình ảnh.
AlexNet
Alex Krizhevsky, một sinh viên tốt nghiệp tại Đại học Toronto, đã quyết định áp dụng mạng nơ-ron vào ImageNet vào năm 2012, mặc dù các giải pháp tương tự trước đó không thành công. Mạng nơ-ron của anh ấy, được gọi là AlexNet, có một số điểm đặc biệt. AlexNet sử dụng nhiều lớp ẩn và phần cứng tính toán nhanh hơn để xử lý tất cả các phép toán phức tạp. Kết quả là, AlexNet vượt trội hơn các phương pháp khác hơn 10%. Nó chỉ sai 3 trong số 20 hình ảnh. Nếu so sánh điểm số, AlexNet đạt điểm B vững chắc trong khi các kỹ thuật khác chỉ đạt điểm C thấp. Từ năm 2012, các giải pháp mạng nơ-ron đã chiếm lĩnh cuộc thi hàng năm và kết quả ngày càng tốt hơn. Hơn nữa, AlexNet đã khơi dậy một làn sóng nghiên cứu về mạng nơ-ron, và chúng ta đã bắt đầu áp dụng chúng vào nhiều lĩnh vực khác ngoài nhận dạng hình ảnh.
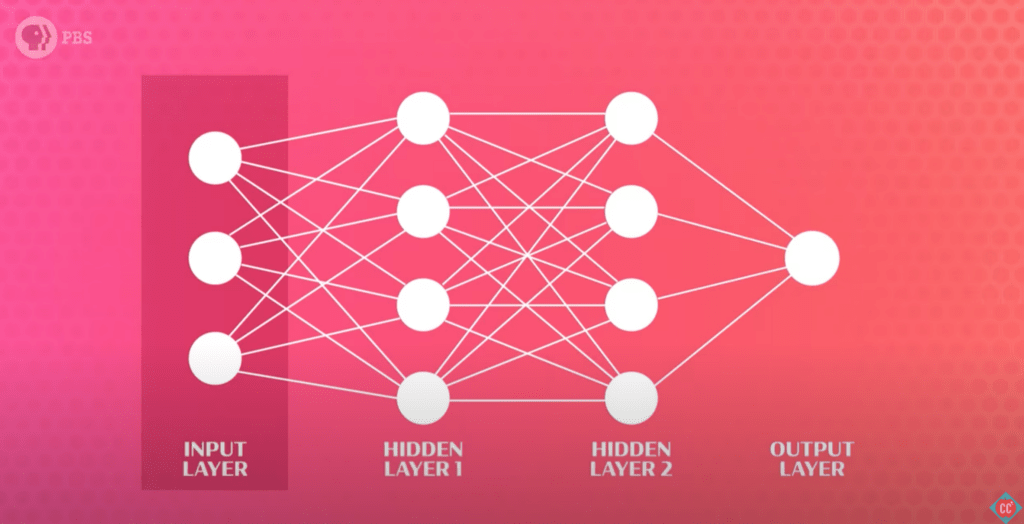
Các lớp ẩn
Để hiểu cách mạng nơ-ron hoạt động, chúng ta cần biết về cấu trúc của chúng. Mạng nơ-ron có ba phần chính: lớp đầu vào, lớp đầu ra và các lớp ẩn ở giữa. Chúng ta sẽ dùng ví dụ về mạng perceptron nhiều lớp để giải thích.
Lớp đầu vào là nơi mạng nơ-ron nhận dữ liệu, được biểu diễn dưới dạng số. Mỗi nơ-ron đầu vào đại diện cho một đặc điểm của dữ liệu. Ví dụ, nếu bạn đang nói về số gam đường trong một chiếc bánh donut, thì mỗi nơ-ron đầu vào sẽ đại diện cho một số gam đường.
Âm thanh có thể được biểu diễn dưới dạng biên độ của sóng âm. Mỗi đặc điểm sẽ có một số đại diện cho biên độ tại một thời điểm. Các từ trong một đoạn văn có thể được biểu diễn bằng số lần mỗi từ xuất hiện. Mỗi đặc điểm sẽ có tần suất của một từ.
Nếu chúng ta đang cố gắng nhận diện một hình ảnh của một con chó, mỗi đặc điểm sẽ đại diện cho thông tin về một điểm ảnh. Đối với hình ảnh đen trắng, mỗi đặc điểm sẽ có một số đại diện cho độ sáng của một điểm ảnh. Đối với hình ảnh màu, mỗi điểm ảnh sẽ được biểu diễn bằng ba số: lượng màu đỏ, xanh lá cây và xanh dương.
Khi các đặc điểm đã có dữ liệu, mỗi đặc điểm sẽ gửi số của nó đến mọi nơ-ron trong lớp tiếp theo, gọi là lớp ẩn. Sau đó, mỗi nơ-ron trong lớp ẩn sẽ kết hợp các số mà nó nhận được để xử lý.

Kết luận
Để kết luận, mục tiêu của mạng nơ-ron trong nhận dạng hình ảnh là xác định các thành phần cụ thể trong dữ liệu đầu vào. Mỗi nơ-ron trong lớp ẩn thực hiện các phép toán phức tạp và gửi kết quả đến các nơ-ron ở lớp tiếp theo. Cuối cùng, lớp đầu ra sẽ tổng hợp các kết quả này để đưa ra câu trả lời cuối cùng.
Ví dụ, nếu chúng ta muốn xác định xem một hình ảnh có phải là hình ảnh của một con chó hay không, chúng ta sẽ có một nơ-ron đầu ra đại diện cho câu trả lời này. Nếu có nhiều nhãn khác nhau, mỗi nơ-ron đầu ra sẽ tương ứng với xác suất của từng nhãn, và chúng ta sẽ chọn nhãn có xác suất cao nhất.
Tóm lại, chìa khóa của mạng nơ-ron và trí tuệ nhân tạo chính là toán học.