
Series này mình sẽ giới thiệu về nền tảng thống nhất phổ biến nhất cho phân tích dữ liệu lớn – Databricks. Nội dung được chia ra làm 2 phần:
- Bảy khái niệm và tính năng cốt lõi của Databricks
- Cách chúng tương tác để giải quyết các vấn đề thực tế trong thế giới dữ liệu hiện đại.
Đầu tiên, có các data warehouses. Chúng lưu trữ dữ liệu dưới dạng hàng và cột vì vào thời điểm đó, Internet và máy tính chỉ có khả năng phân phối thông tin văn bản đơn giản. Sau này, các data lakes xuất hiện — chúng có thể lưu trữ gần như mọi loại dữ liệu mà bạn có thể thu thập. Data lakes đặc biệt hữu ích trong thời đại của mạng xã hội và YouTube.
Tuy nhiên, cả hai đều có nhược điểm — data warehouses rất đắt đỏ và không phù hợp với khoa học dữ liệu hiện đại, trong khi data lakes thì hỗn độn và thường trở thành data swamps. Do đó, các công ty bắt đầu sử dụng hai hệ thống công nghệ riêng biệt — data warehouses dành cho BI và phân tích, còn data lakes dành cho máy học.
Tuy nhiên, việc quản lý hai kiến trúc dữ liệu khác nhau này gặp rất nhiều khó khăn, dẫn đến hiệu quả kém. Vấn đề này đã thúc đẩy sự ra đời của kiến trúc lakehouse, đây chính là điểm nổi bật của Databricks.
Databricks là một nền tảng đám mây cho phép người dùng khai thác giá trị từ cả data warehouses và data lakes trong một môi trường hợp nhất. Bài viết này sẽ cung cấp một cái nhìn tổng quan về nền tảng, giới thiệu những tính năng quan trọng nhất và cách sử dụng chúng.
Những gì chúng ta sẽ đề cập trong hướng dẫn Databricks này
Databricks là một nền tảng khổng lồ đến mức tài liệu hướng dẫn của nó có thể biến thành một cuốn sách. Do đó, mục tiêu của bài viết là cung cấp cho bạn một hệ thống các khái niệm — giải thích các tính năng của Databricks theo thứ tự tuyến tính, giúp bạn từ người mới bắt đầu trở thành một người sử dụng Databricks thành thạo.
1. Databricks là gì?
Khi bạn đọc đến từ Databricks, bạn nên nghĩ ngay đến nó như một nền tảng, chứ không phải là một framework hay thư viện Python.
Thông thường, các nền tảng cung cấp một loạt các tính năng, và Databricks cũng không ngoại lệ. Đây là một trong số rất ít nền tảng có thể được sử dụng bởi bất kỳ chuyên gia dữ liệu nào, từ kỹ sư dữ liệu đến kỹ sư máy học hiện đại (hoặc như báo chí ngày nay gọi là lập trình viên AI).
Databricks có các thành phần cốt lõi sau:
- Workspace: Databricks cung cấp một môi trường tập trung nơi các nhóm có thể cộng tác mà không gặp bất kỳ rắc rối nào. Môi trường này có thể truy cập thông qua giao diện web thân thiện với người dùng.
- Notebooks: Databricks có một phiên bản Jupyter notebooks được thiết kế riêng cho mục đích cộng tác và linh hoạt.
- Apache Spark: Databricks rất yêu thích Apache Spark. Đây là động cơ vận hành tất cả các quá trình xử lý song song của các tập dữ liệu khổng lồ, làm cho nó phù hợp với phân tích dữ liệu lớn.
- Delta Lake: Cải tiến trên các hồ dữ liệu bằng cách cung cấp các giao dịch ACID. Delta Lakes đảm bảo độ tin cậy và tính nhất quán của dữ liệu, giải quyết các thách thức truyền thống liên quan đến hồ dữ liệu.
- Scalability: Nền tảng này mở rộng theo chiều ngang thay vì chiều dọc, rất phù hợp với các tổ chức đang đối mặt với nhu cầu dữ liệu ngày càng tăng.
2. Lợi ích của Databricks
Các thành phần này, khi kết hợp lại, mang đến một loạt lợi ích:
- Cộng tác giữa các nhóm: Kỹ sư, nhà phân tích, nhà khoa học dữ liệu và kỹ sư Machine Learning có thể làm việc liền mạch trên cùng một nền tảng.
- Tính nhất quán: Với notebooks, người dùng có thể chuyển đổi giữa các nhiệm vụ và ngôn ngữ lập trình mà không cần thay đổi ngữ cảnh.
- Quy trình làm việc hiệu quả: Người dùng có thể thực hiện các nhiệm vụ như làm sạch dữ liệu, biến đổi dữ liệu, và học máy một cách đồng bộ.
- Quản lý dữ liệu tích hợp: Người dùng có thể nhập dữ liệu vào nền tảng từ nhiều nguồn, tạo bảng, và chạy SQL.
- Cộng tác thời gian thực: Tính năng chỉnh sửa và chia sẻ notebooks cho phép cộng tác thời gian thực. Nhiều thành viên trong nhóm có thể làm việc trên cùng một notebook cùng lúc.
3. Thiết lập tài khoản
Để thiết lập tài khoản của bạn, truy cập https://www.databricks.com/try-databricks và đăng ký Community Edition.

Community Edition có ít tính năng hơn so với phiên bản Enterprise, nhưng không yêu cầu thiết lập nhà cung cấp đám mây, điều này rất phù hợp cho các trường hợp sử dụng nhỏ như hướng dẫn.
Nếu bạn thấy trang này sau khi xác minh email, bạn đã sẵn sàng để bắt đầu:
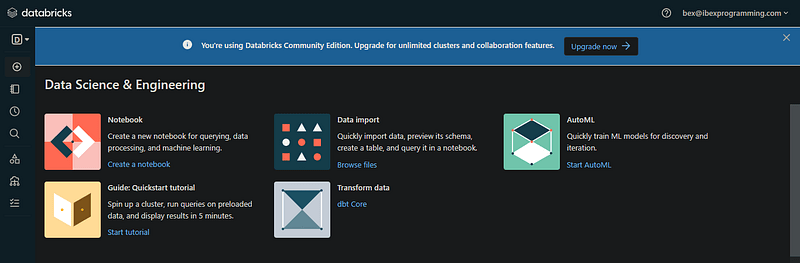
4. Databricks Workspace
Giao diện mà bạn nhìn thấy là Workspace dành cho địa chỉ email của bạn (workspace của Community Edition có thể dễ dàng tìm thấy). Trên thực tế, thường thì một quản trị viên tài khoản từ công ty của bạn sẽ tạo một tài khoản Databricks duy nhất và quản lý quyền truy cập vào workspace.
Bây giờ, hãy cùng tìm hiểu giao diện người dùng của nền tảng. Ở bảng điều khiển bên trái, chúng ta có menu cho các thành phần khác nhau mà Databricks cung cấp. Phiên bản Enterprise sẽ có nhiều nút hơn nữa:
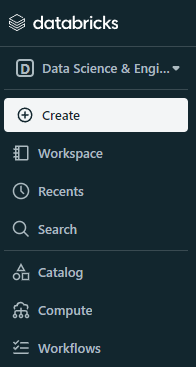
Tùy chọn đầu tiên trong menu là loại workspace, mặc định được đặt là data science and engineering. Nếu bạn có thể thay đổi nó thành machine learning, một tùy chọn Experiments mới sẽ xuất hiện:
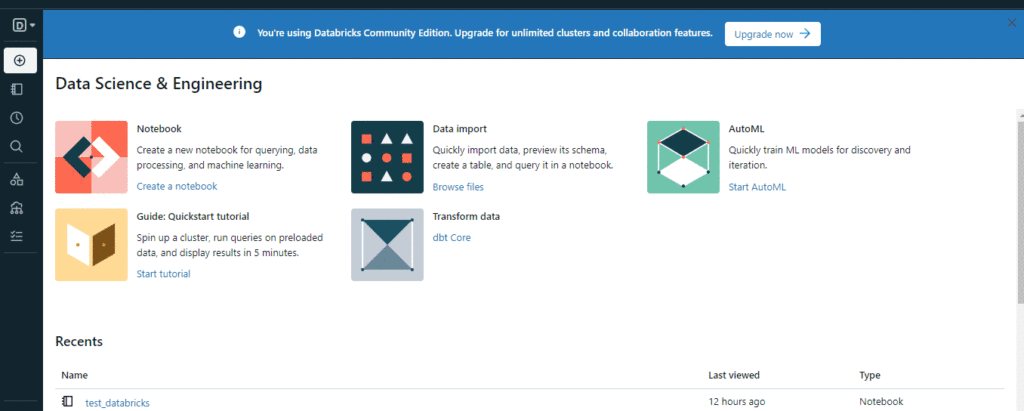
Thoạt nhìn, có thể trông như không làm được gì nhiều, nhưng khi bạn nâng cấp tài khoản và bắt đầu khám phá, bạn sẽ nhận ra một số tính năng tuyệt vời của nền tảng:
- Central hub for resources: notebooks, clusters, tables, libraries và dashboards
- Notebooks hỗ trợ nhiều ngôn ngữ
- Cluster management quản lý tài nguyên tính toán cho workspace để thực thi mã
- Table management
- Dashboard creation: Người dùng DB có thể thu thập các hình ảnh trực quan vào dashboards ngay trong workspace
- Chỉnh sửa notebook thời gian thực và hợp tác
- Kiểm soát phiên bản cho notebooks
- Job scheduling (một tính năng mạnh mẽ): người dùng có thể thực thi notebooks và scripts tại các khoảng thời gian chỉ định
- Và nhiều tính năng khác.
Bây giờ, hãy cùng xem xét kỹ hơn một số thành phần này.
5. Databricks Clusters
Clusters trong Databricks đề cập đến các tài nguyên tính toán được sử dụng để thực thi các nhiệm vụ xử lý dữ liệu. Thông thường, các clusters này được cung cấp bởi nhà cung cấp đám mây mà bạn chọn trong quá trình thiết lập tài khoản.
Clusters của Community Edition bị giới hạn về RAM và CPU, và không bao gồm GPU. Tuy nhiên, người dùng phiên bản cao cấp có thể dễ dàng thực hiện các tác vụ sau với clusters:
- Data processing: Clusters được sử dụng để xử lý và chuyển đổi khối lượng lớn dữ liệu, tận dụng sức mạnh xử lý song song của Spark.
- Machine learning: Bạn có thể sử dụng Python (hoặc bất kỳ ngôn ngữ nào khác) và các thư viện của nó để huấn luyện và suy luận mô hình.
- ETL workflows: Clusters cũng hỗ trợ các quy trình Extract, Transform, Load bằng cách xử lý và chuyển đổi dữ liệu từ nguồn đến đích một cách hiệu quả.
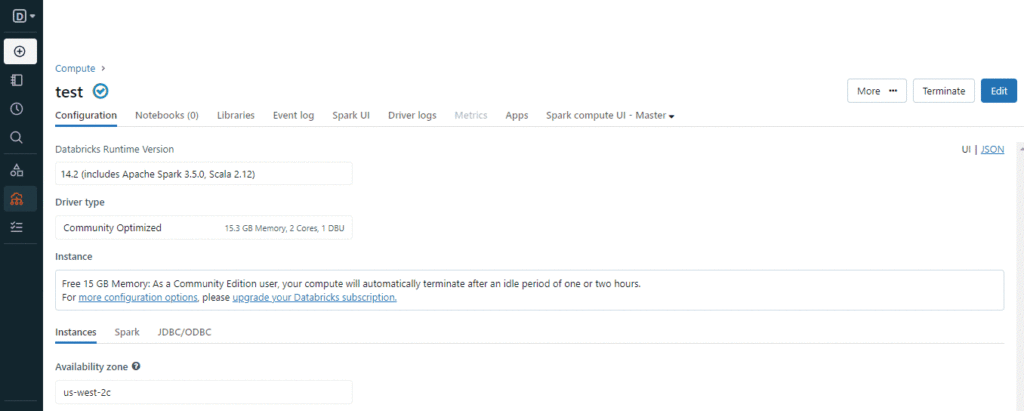
Để tạo một cluster, bạn có thể sử dụng nút “Create” hoặc tùy chọn “Compute” từ menu:

Khi tạo cluster, hãy chọn phiên bản Spark phù hợp với môi trường của bạn và đợi vài phút để nó hoạt động.
6. Databricks Notebooks
Khi bạn đã có một cluster đang hoạt động, bạn có thể bắt đầu tạo notebooks.
Nhưng trong một thế giới mà Jupyter thực sự tồn tại, tại sao lại chọn một cái gì đó “giống Jupyter”? Thực tế, Databricks notebooks có những ưu điểm sau so với Jupyter notebooks:
- Collaboration: Các tính năng cộng tác tích hợp cho phép nhiều người dùng làm việc trên cùng một notebook cùng lúc. Các thay đổi được theo dõi theo thời gian thực.
- Execution environment: Hầu hết các nhà cung cấp môi trường Jupyter hoặc các phiên bản cài đặt cục bộ dựa vào các máy đơn với phần cứng được xác định trước. Người dùng phải tự cài đặt các thư viện và phụ thuộc bên ngoài. Ngược lại, Databricks notebooks được hỗ trợ bởi các clusters, tự động quản lý tài nguyên và mở rộng theo khối lượng công việc. Chúng cũng đi kèm với các môi trường đã được thiết lập sẵn.
- Integration with Big Data tech: Jupyter có thể làm việc với Apache Spark, nhưng người dùng cần quản lý các phiên Spark và phụ thuộc một cách thủ công. Vì Databricks được sáng lập bởi các người sáng lập Spark, nền tảng hỗ trợ framework này một cách bản địa. Các phiên Spark và clusters được quản lý tự động bởi nền tảng Databricks.
Có nhiều ưu điểm khác của Databricks notebooks so với Jupyter, vì vậy dưới đây là bảng tổng hợp các điểm khác biệt:
| Feature | Jupyter Notebooks | Databricks Notebooks |
| Platform | Mã nguồn mở, chạy cục bộ hoặc trên các nền tảng đám mây | Chỉ dành riêng cho nền tảng Databricks |
| Collaboration and Sharing | Tính năng cộng tác hạn chế, chia sẻ thủ công | Cộng tác tích hợp, chỉnh sửa đồng thời theo thời gian thực |
| Execution | Dựa vào máy chủ cục bộ hoặc bên ngoài | Thực thi trên các Databricks clusters |
| Integration with Big Data | Có thể tích hợp với Spark, yêu cầu cấu hình bổ sung | Tích hợp bản địa với Apache Spark, tối ưu hóa cho dữ liệu lớn |
| Built-in Features | Công cụ/phần mở rộng bên ngoài cho kiểm soát phiên bản, cộng tác và trực quan hóa | Tích hợp với các tính năng riêng của Databricks như Delta Lake, hỗ trợ tích hợp các công cụ cộng tác và phân tích |
| Cost and Scaling | Cài đặt cục bộ thường miễn phí, giải pháp dựa trên đám mây có thể có chi phí | Dịch vụ trả phí, chi phí phụ thuộc vào mức sử dụng, mở rộng liền mạch với các Databricks clusters |
| Ease of Use | Quen thuộc và được sử dụng rộng rãi trong cộng đồng khoa học dữ liệu | Được tối ưu hóa cho phân tích dữ liệu lớn, có thể có đường cong học tập dốc hơn đối với các tính năng riêng của Databricks |
| Data Visualization | Hỗ trợ trực quan hóa dữ liệu hạn chế | Hỗ trợ tích hợp trực quan hóa dữ liệu trong môi trường notebook |
| Cluster Management | Người dùng cần quản lý các phiên Spark và phụ thuộc thủ công | Nền tảng Databricks tự động xử lý quản lý cluster và mở rộng |
| Use Cases | Đa năng cho các nhiệm vụ khoa học dữ liệu khác nhau | Chuyên biệt cho phân tích dữ liệu lớn cộng tác trong nền tảng Databricks |
Cuối cùng, những lợi ích trên của Databricks notebooks sẽ phát huy hiệu quả trong các trường hợp sử dụng cụ thể. Nếu bạn chỉ muốn thao tác với một tập dữ liệu CSV bằng Pandas trên máy tính xách tay của mình, Jupyter sẽ là lựa chọn tốt hơn.
Tuy nhiên, đối với các ứng dụng ở cấp doanh nghiệp, Databricks như một nền tảng có thể là lựa chọn tốt hơn.

One Reply to “Hướng dẫn Databricks: 7 Khái niệm Cần Biết (Phần…”