1. Absolute XPath (XPath tuyệt đối)
XPath tuyệt đối bắt đầu bằng dấu gạch chéo đơn “/”, cho phép xác định một đường dẫn tuyệt đối đến đối tượng UI.
Ví dụ: /html/body/div[2]/div/div[2]/div[1]/div[2]/form/div/input
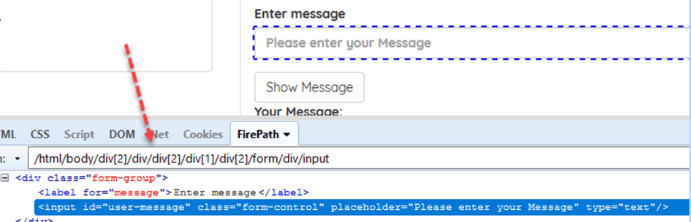
- Ưu điểm: Tìm kiếm dễ dàng
- Nhược điểm: Nếu có bất kỳ thay đổi nào trên đường dẫn của element thì XPath lấy sẽ sai
2. Relative XPath (XPath tương đối)
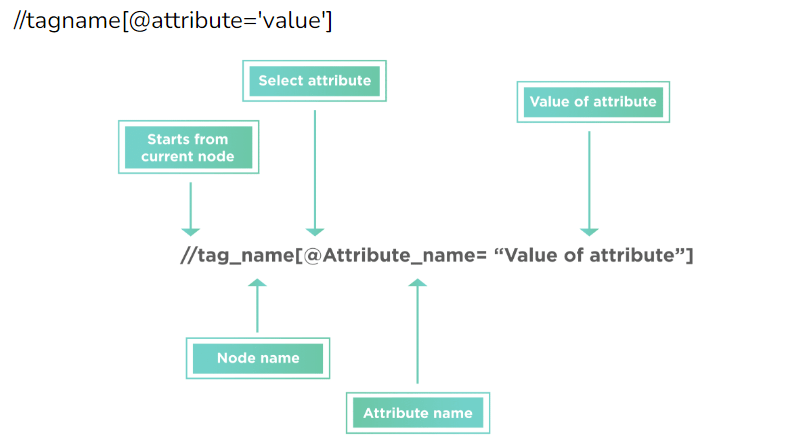
- XPath tương đối bắt đầu bằng 2 dấu gạch chéo “//”, cho phép xác định một đối tượng UI ở bất kỳ đâu trên trang web, không cần bắt đầu bởi thẻ html trong đường dẫn, không cần phải viết XPath dài.
Ví dụ: //div[@class = ‘form-group’]//input[@id = ‘user-message’]
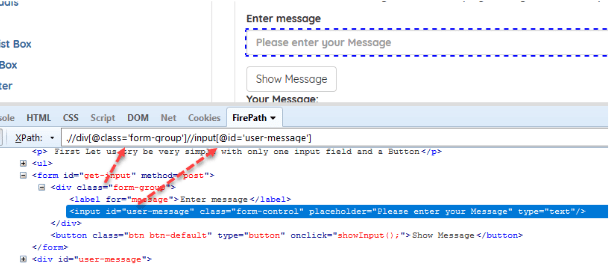
- Relative XPath format
3. Locator priority
- 1 – Unique: Giá trị của attribute phải là duy nhất (không bị trùng)
- 2 – Meaning: Giá trị của attribute có liên quan đến field đó (có id/ class/ name nhưng phải có nghĩa)
- 3 – Attribute: id/class/name (Ưu tiên 3 loại này vì nó chạy nhanh hơn)
- 4 – Attribute non (id/class/name): Dùng bất kì attribute nào mà duy nhất (1) và có ý nghĩa (2)
- 5 – Link: Không nên dùng với attribute là href – nên dùng với text hoặc title
Lưu ý:
- Không sử dụng tag name với dấu *:
- ví dụ: //*[@id = ‘login_username’]
- => Chạy chậm hơn và dễ gây hiểu nhầm/ khó đọc
- Không nên sử dụng attribute value nằm trong nháy đôi:
- ví dụ: //input[@id = “login_username”]
- => Làm cho code xấu