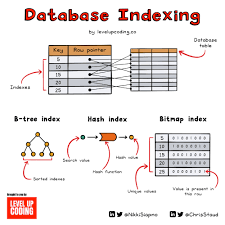

Index là gì ?
Nói ngắn gọn thì Index là 1 thuật toán, cấu trúc dữ liệu giúp database có thể tìm kiếm record nhanh hơn.
Nếu không có index thì database sẽ quét toàn bộ bảng và so sánh điều kiện rồi đưa record vào result nếu điều kiện phù hợp. Trung bình độ phức tạp là O(N/2).
Nếu database chỉ có ít record thì sẽ không có vấn đề gì với phương pháp trên. Nhưng nếu database có size lớn với hàng triệu bản ghi thì việc tìm kiếm bằng cách đi qua từng record tốn rất nhiều thời gian, có thể mất từ 5-6s đến hơn 60s…
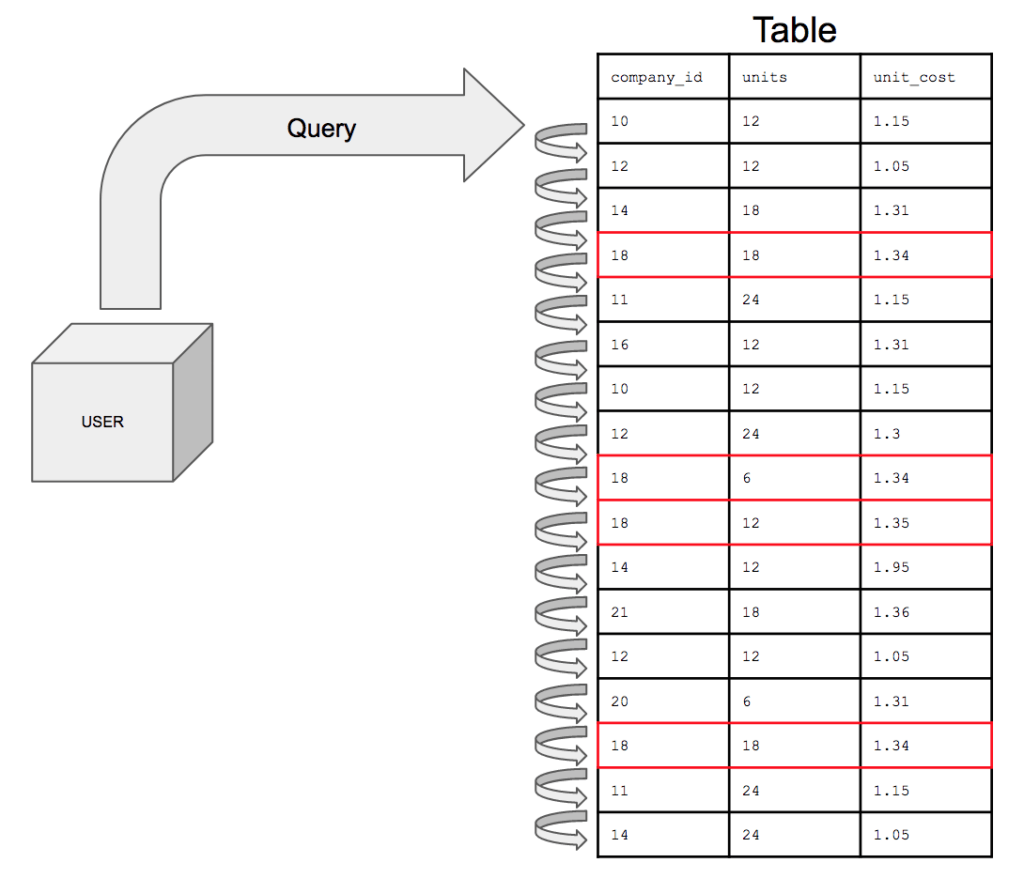
Database indexes hoạt động bên dưới bề mặt như nào ?
Để giải quyết bài toán tốc độ querry chậm phải giải tối ưu được thuật toán tìm kiếm cho querry.
Bản chất là index là một cấu trúc dữ liệu (b-tree) lưu trữ con trỏ đến vị trí lưu trữ dữ liệu để tối ưu tìm kiếm. Điều này sẽ chuyển bài toán từ tìm kiếm tuần tự với đọ phức tạp O(N/2) thành bài toán b-tree O(logn)
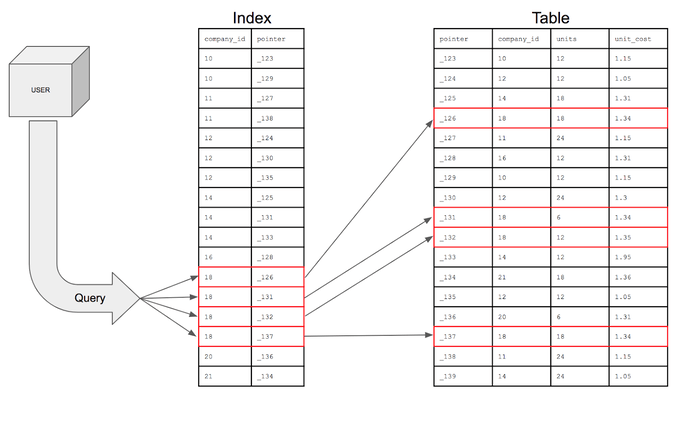
Nhược điểm của index
Tuy là index mang lại rất nhiều lợi ích nhưng song song với đó cũng có những đánh đổi nhất định. Các developer nên cân nhắc cẩn thận khi sử dụng index chứ không nên dùng 1 cách bừa bãi.
1. Memory: Do indexing sử dụng thêm cấu trúc dữ liệu bổ sung để tăng tốc tìm kiếm nên điều này sẽ mang lại gánh nặng nhất định cho bộ nhớ. Nếu 1 table chỉ có 1 index thì lượng bộ nhớ sử dụng sẽ không đáng kể so với size của database nhưng nếu dùng bữa bãi vd: 1 table có 100 column thì tạo 100 index => lượng memory sử dụng sẽ rất lớn
2. Speed insert/update: Việc sử dụng thêm 1 cấu trúc dữ liệu để tăng tốc độ truy vấn sẽ yêu cầu việc cập nhật dữ liệu này bằng 1 thuật toán nhất định khi insert, update. Điều này sẽ không ảnh hưởng khi truy vấn nhưng sẽ tốn thêm tài nguyên khi insert, update. Điều này nên được cân nhắc đối với những table ít được querry và tần suất insert update cao
B-tree
B-tree là thuật toán mặc định khi sử dụng index. Về cơ bản b-tree là một dạng cải tiến của Binary Search Tree (BST).
Những hạn chế của BST có thể gây khó chịu. B-Tree là cấu trúc dữ liệu đa năng có thể xử lý lượng dữ liệu khổng lồ một cách dễ dàng. Khi cần lưu trữ và tìm kiếm lượng lớn dữ liệu, BST có thể trở nên không thực tế do hiệu suất kém và mức sử dụng bộ nhớ cao. B-tree là một loại cây tự cân bằng được thiết kế đặc biệt để khắc phục những hạn chế này.
Không giống như BST, B-tree được đặc trưng bởi số lượng lớn khóa mà chúng có thể lưu trữ trong một nút duy nhất. Mỗi nút trong B-tree có thể chứa nhiều khóa, điều này cho phép cây có hệ số phân nhánh lớn hơn và do đó có chiều cao thấp hơn. Chiều cao nông này dẫn đến ít I/O ổ đĩa hơn, dẫn đến các hoạt động tìm kiếm và chèn nhanh hơn. B-tree đặc biệt phù hợp với các hệ thống lưu trữ có khả năng truy cập dữ liệu chậm và cồng kềnh như ổ cứng, bộ nhớ flash và CD-ROM.
B-tree duy trì sự cân bằng bằng cách đảm bảo rằng mỗi nút có số lượng khóa tối thiểu nên cây luôn được cân bằng. Sự cân bằng này đảm bảo rằng độ phức tạp về thời gian cho các thao tác như chèn, xóa và tìm kiếm luôn là O(log n), bất kể hình dạng ban đầu của cây
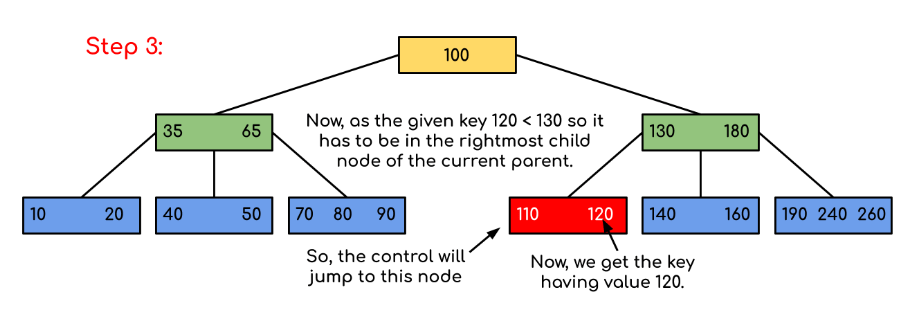
Thuộc tính của B-tree:
- Tất cả các lá đều ở cùng cấp độ.
- B-Tree được định nghĩa bằng thuật ngữ mức độ tối thiểu ‘ t ‘. Giá trị của ‘ t ‘ phụ thuộc vào kích thước khối đĩa.
- Mọi nút ngoại trừ nút gốc phải chứa ít nhất các khóa t-1. Thư mục gốc có thể chứa tối thiểu 1 khóa.
- Tất cả các node (bao gồm cả root) có thể chứa tối đa ( 2*t – 1 ) keys.
- Số lượng node con của một node bằng số lượng key trong node đó cộng với 1 .
- Tất cả các key của một node được sắp xếp theo thứ tự tăng dần. Con giữa hai khóa k1 và k2 chứa tất cả các khóa trong phạm vi từ k1 và k2 .
- B-tree phát triển và co lại từ gốc, không giống như Cây tìm kiếm nhị phân. Cây tìm kiếm nhị phân phát triển hướng xuống và cũng co lại từ hướng xuống.
- Giống như các Cây tìm kiếm nhị phân cân bằng khác, độ phức tạp về thời gian để tìm kiếm, chèn và xóa là O(log n).
- Việc chèn Node vào B-tree chỉ xảy ra tại node Lá.

3 Replies to “How do DATABASE INDEX work?”