Hãy cùng xem xét ví dụ thực tiễn dưới đây:
Có 1 mảng 10tr phần tử, được lưu bằng 2 cấu trúc:
- Array: giá trị của các phần tử được lưu cạnh nhau trên Ram (contiguous)
- LinkedList: giá trị của các phần tử lưu rải rác trên Ram (non-contiguous)
const int SIZE = 10'000'000;
std::vector<int> arr(SIZE, 1); // Array
std::list<int> lst(SIZE, 1); // LinkedListPhép thử: Read & Write : Đọc giá trị từng phần tử và tăng giá trị lên 1
for (int i = 0; i < SIZE; ++i) {
sum += arr[i]; // read
arr[i] += 1; // write
}
for (int& val : lst) {
sum += val; // read
val += 1; // write
}Kết quả:
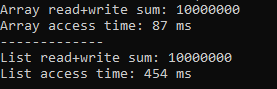
Tốc độ lệch nhau khoảng ~5 lần.
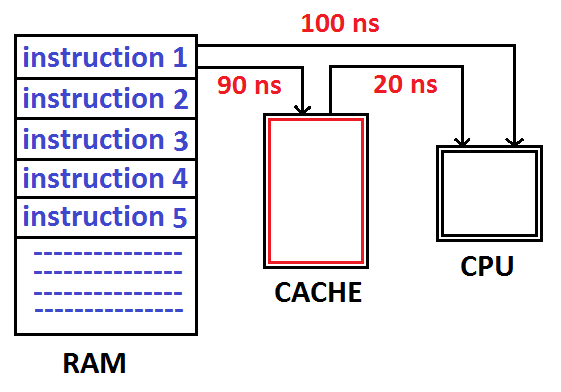
Lý do cho sự khác biệt tốc độ nằm ở việc Cpu cache hit & cache miss
Cpu vốn có tốc độ rất cao, nhưng không phải lúc nào phần mềm cũng tận dụng được hết sức mạnh này. Hiểu nôm na: 1 dev có tốc độ làm rất tốt, nhưng PM không giao kịp việc, nên hay ở trạng thái ngồi chơi.
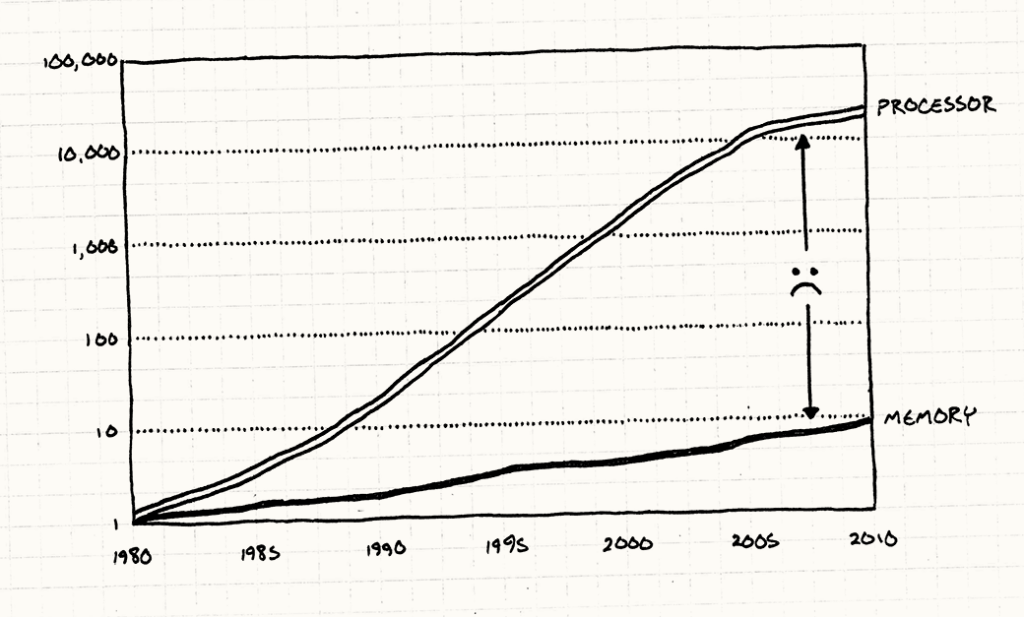
(Theo định luật Moore, tốc độ CPU ngày càng tăng, nhưng các phần hardware khác thì không có sự tăng trưởng tưng ứng)
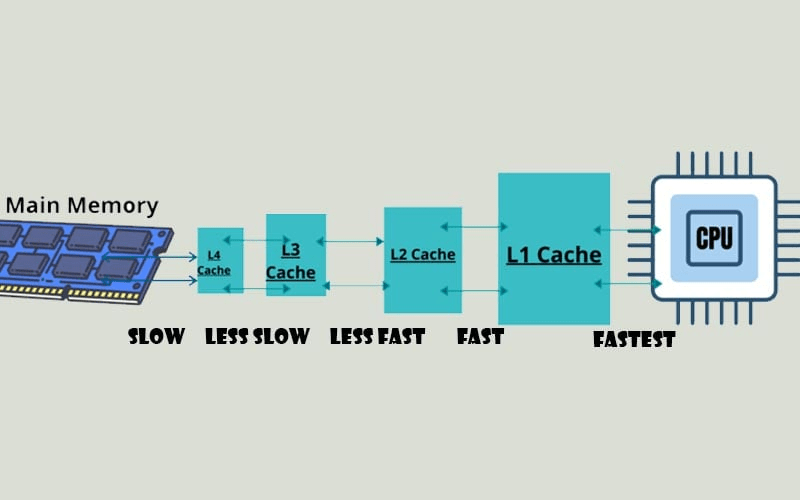
Vì vậy, để giải quyết vấn đề Cpu ngồi chơi quá nhiều, các kỹ sư đã add riêng cho mỗi Cpu 1 “backlog” công việc, để làm xong “task” này thì vào “backlog” lấy việc khác mà làm, không ngồi chơi. “Backlog” này được gọi là Cache.
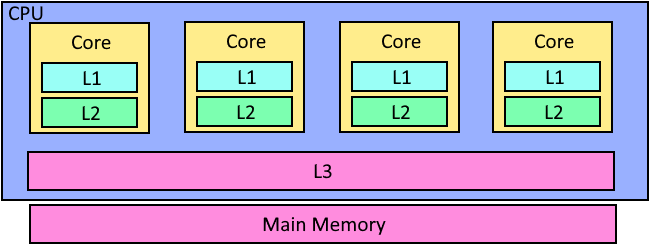
(Hình minh họa logic)

(Ảnh chụp thật + note các vùng)
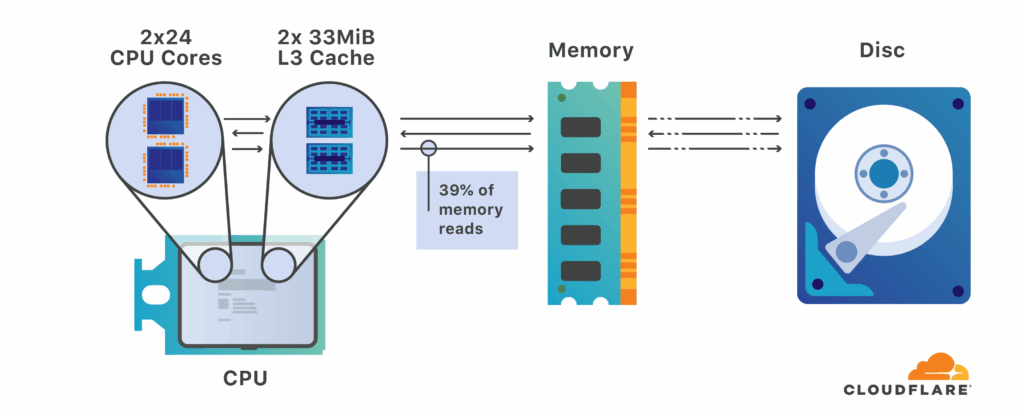
CPU hiện đại có nhiều Core, mỗi Core có cache riêng của nó (L1, L2), và toàn bộ Core trong một Cpu thì có chung cache L3. Giống như “backlog” của cả team Dev.
Mỗi khi CPU định làm 1 “task”, việc đầu tiên nó sẽ nhìn vào “backlog” / cache riêng của mình, nếu không có cái nó muốn tìm, thì sẽ tiếp tục nhìn vào L3, nếu vẫn không có thì mới hỏi PM / Ram: có task nào không ?
Vì vậy, để tận dụng được hết năng lực của Cpu / Core, việc đẩy data vào Cache nhanh nhất có thể là việc quan trọng.
Giờ chúng ta đã hiểu cách CPU nhận việc, tiếp theo cần hiểu: Vì sao trong ví dụ ban đầu, Array lại nhanh hơn LinkedList ?
Câu trả lời nằm ở “chiến thuật” load data vào Cache.
Mỗi khi load data vào cache, các vùng-nằm-cạnh-nhau (contiguous) trên Ram sẽ có xu hướng được load vào cùng theo batch.
Array thỏa mãn điều kiện này, nên các phần tử có xác xuất được vào cache cùng nhau cao hơn so với LinkedList (nằm rải rác) ==> Nên khi Cpu cần data, tỷ lệ Cpu có được cái mình cần cao hơn ==> Tăng tốc độ tính toán.