
Ngôn ngữ là một công cụ để con người diễn đạt và giao tiếp, phát triển từ thời thơ ấu và suốt cả cuộc đời. Còn máy móc không thể tự nhiên nắm bắt được khả năng hiểu và giao tiếp bằng ngôn ngữ, trừ khi được trang bị các thuật toán trí tuệ nhân tạo (AI). Điều này là một thách thức và đòi hỏi sự nghiên cứu lâu dài để đạt được, để máy móc có thể đọc, viết và giao tiếp giống như con người. Thế là chặng đường phát triển mô hình ngôn ngữ (Language Model) bắt đầu.
LM là gì?
Về mặt kỹ thuật, Language Model (LM) là một trong những phương pháp chính để nâng cao khả năng ngôn ngữ của máy móc. LM nhắm đến việc mô hình hóa khả năng sinh ra của các chuỗi từ và dự đoán xác suất của các từ xuất hiện trong tương lai (hoặc bị thiếu).
Nghiên cứu về mô hình ngôn ngữ đã nhận được sự chú ý rộng rãi, có thể chia thành bốn giai đoạn phát triển chính như sau:
- Statistical language models (SLM)
- Neural language models (NLM)
- Pre-trained language models (PLM)
- Large language models (LLM)
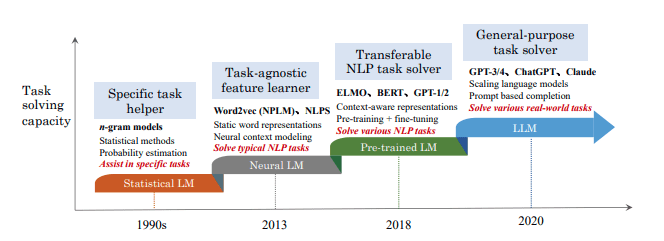
Statistical Language Model (SLM)
Count-Based Approach
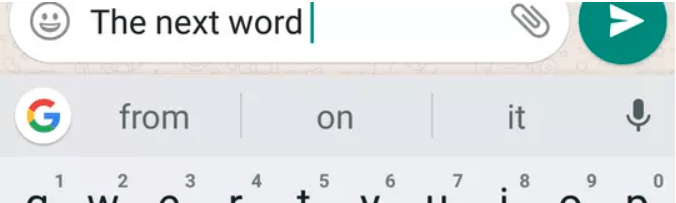
Chắc hẳn mọi người đã từng nhắn tin trên điện thoại và gặp tính năng gợi ý từ như này:
Hoặc khi sử dụng các công cụ tìm kiếm:
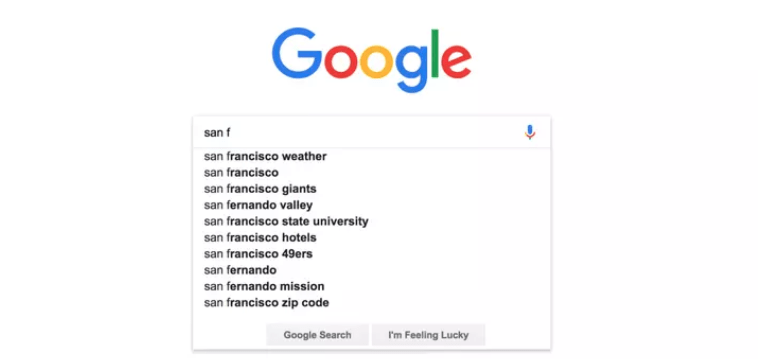
Phương pháp cơ bản nhất của Mô hình Ngôn ngữ Thống kê (SLM) là tính toán xác suất của từ tiếp theo dựa trên số lần xuất hiện của chuỗi đó trong tập văn bản (corpus) khi đã biết các từ trước đó.
Conditional Probability and Chain Rule:
Xác suất có điều kiện là xác suất của một sự kiện xảy ra khi một sự kiện khác đã xảy ra trước đó. Nó được biểu diễn như sau cho các sự kiện A và B.
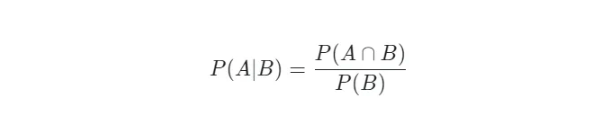
Từ phương trình trên, có thể suy ra phương trình sau đây.
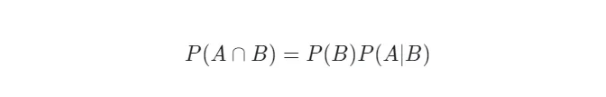
Tổng quát hóa điều này cho n sự kiện, chúng ta có thể dễ dàng suy luận điều sau đây đúng cho các sự kiện A1,A2,…,An theo cách quy nạp.
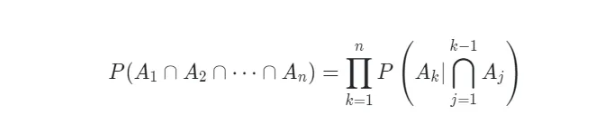
Kết quả tổng quát này được gọi là Qui luật chuỗi cho Xác suất có điều kiện.
Bằng cách sử dụng xác suất có điều kiện, chúng ta có thể biểu diễn xác suất của một câu. Xác suất của một câu S được tạo thành từ các từ w₁, w₂, … ,wₙ có thể được biểu diễn như sau:
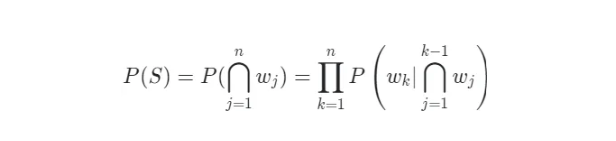
Ví dụ, xác suất cho câu “A little boy smiles”:
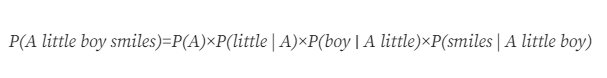
Việc tính giá trị P(w1…wn) trong trường hợp n vô hạn, thực tế là vô cùng khó khăn. Để giảm độ phức tạp cho việc tính toán cũng như tạo ra một hướng đi khả thi để có thể mô hình hóa ngôn ngữ, mô hình n-gram ra đời. Mô hình n-gram giả định việc mô hình ngôn ngữ là một chuỗi Markov, thỏa mãn tính chất Markov. Chúng ta có tính chất Markov được định nghĩa như sau:
Một quá trình mang tính ngẫu nhiên có thuộc tính Markov nếu phân bố xác suất có điều kiện của các trạng thái tương lai của quá trình, khi biết trạng thái hiện tại, phụ thuộc chỉ vào trạng thái hiện tại đó
N-gram Language Model
N-gram có nghĩa là một chuỗi gồm n từ liên tiếp, và trong n-gram language model, một chuỗi gồm n từ trong một tập văn bản được coi là một mã thông báo. Trong trường hợp này, nếu n=1, nó được gọi là unigram, nếu n=2, nó được gọi là bigram, và nếu n=3, nó được gọi là trigram. Nếu n≥4, số này sẽ được gắn trực tiếp vào phía trước của ‘gram’ để đặt tên cho nó.
Ví dụ, chúng ta có câu: W = “today is saturday and tomorrow is sunday”. Khi đó với mô hình bigram:
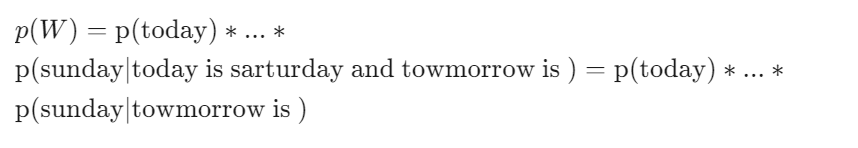
Tức là chúng ta sẽ chỉ xét các từ đứng gần từ đang xét thôi, còn lại thì bỏ qua =))
Limitation
Giả sử chúng ta có câu ‘An adorable little boy is spreading smiles’. Đưa vào ‘An adorable little boy is spreading’, chúng ta muốn dự đoán từ tiếp theo w. Sử dụng 4-gram, chúng ta có thể đoán từ w sử dụng xác suất sau:
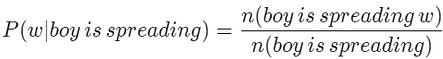
Hãy cho rằng chuỗi ‘boy is spreading’ xuất hiện 1000 lần trong tập văn bản huấn luyện. ‘boy is spreading insults’ và ‘boy is spreading smiles’ xuất hiện 500 và 200 lần. Trong trường hợp này, xác xuất mà w là insults là 50%, và xác suất mà w là smiles là 20%. Theo lựa chọn xác suất, mô hình sẽ đánh giá rằng w=insults. Mô hình ngôn ngữ này đã loại bỏ và không đưa ra chuỗi ‘an adorable little’ trước ‘boy is spreading’. Điểm quan trọng là, trong mô hình n-gram, chỉ có một số giới hạn các chuỗi từ được phản ánh trong dự đoán, vì vậy có thể tạo ra các câu không khớp với ngữ cảnh hoàn toàn, như trong ví dụ trên. Điều đó có nghĩa là nó có độ chính xác thấp hơn so với một mô hình ngôn ngữ xem xét toàn bộ câu. Chắc chắn, nếu bạn tăng kích thước của n, bạn có thể dự đoán câu với độ chính xác cao hơn bằng cách phản ánh ngữ cảnh tốt hơn. Tuy nhiên, khi n tăng, kích thước mô hình tăng và vấn đề thưa thớt trở nên nghiêm trọng. Thế nên việc chọn n là một bài toán đánh đổi.
References: https://arxiv.org/abs/2303.18223
https://medium.com/@redbeet1007/nlp-statistical-language-model-bca51c21d934 https://viblo.asia/p/language-model-la-chi-rua-maGK7Vkb5j2
https://web.stanford.edu/~jurafsky/slp3/3.pdf

