
1. Text-to-image
Step 1:
Stable Diffusion (SD) sinh ra tensor ngẫu nhiên trong latent space (đại diện của dữ liệu nén). Điều chỉnh tensor này bằng cách đặt “seed” của generator để tạo số ngẫu nhiên. Nếu đặt seed là một giá trị cụ thể, thì ta sẽ luôn luôn nhận được cùng 1 tensor ngẫu nhiên. Đây là biểu diễn của hình ảnh trong latent space, tuy nhiên nhưng bây giờ nó chỉ là noise (nhiễu).

Step 2:
Noise-predictor U-Net lấy latent noisy image và text prompt và predict noise
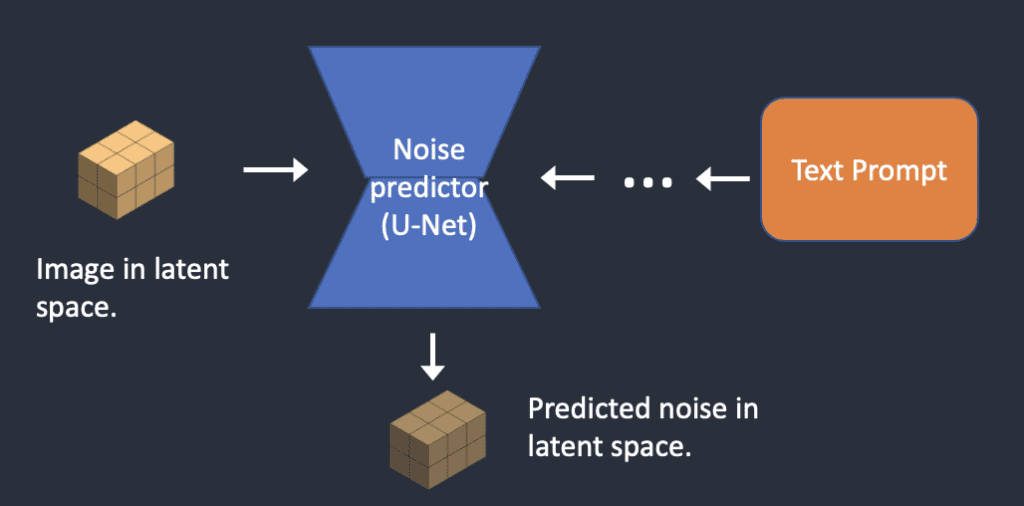
Step 3:
latent image mới = latent image – predicted noise
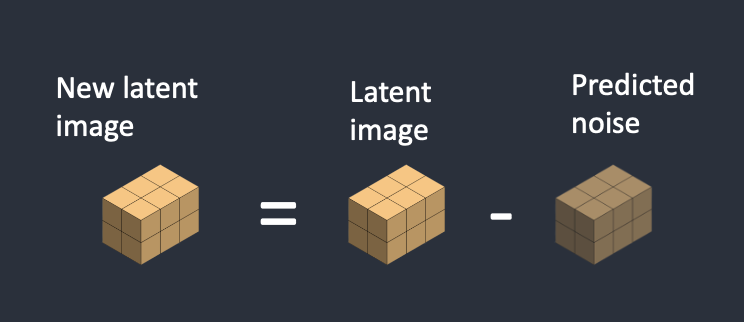
Step 4:
Cuối cùng, VAE convert latent image về pixel. Đây là ảnh sinh ra sau khi chạy SD

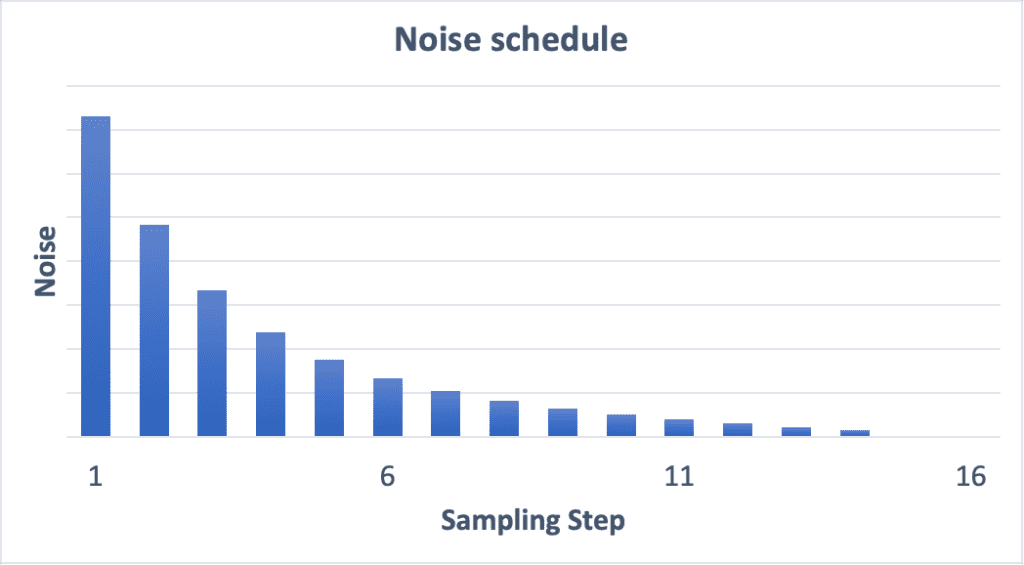
Noise Schedule
noise schedule được dùng để cố gắng lấy expected noise tại mỗi sampling step. Chúng ta có thể chọn trừ cùng 1 số lượng noise tại mỗi step hoặc trừ nhiều hơn lúc bắt đầu,… Noise schedule trừ đi đủ noise để đạt được expected noise ở mỗi bước tiếp theo.
2. Image-to-Image
Là một ứng dụng của SD, có thể được áp dụng với bất kì diffusion model nào.
Image và text prompt sẽ là đầu vào của quá trình image-to-image. Image được sinh ra sẽ được điều khiển bởi cả input image và text prompt. Ví dụ, sử dụng ảnh vẽ và prompt “photo of perfect green apple with stem, water droplets, dramatic lighting”, image-to-image có thể cho ra “professional drawing”

Step 1:
input image sẽ được encode thành latent image
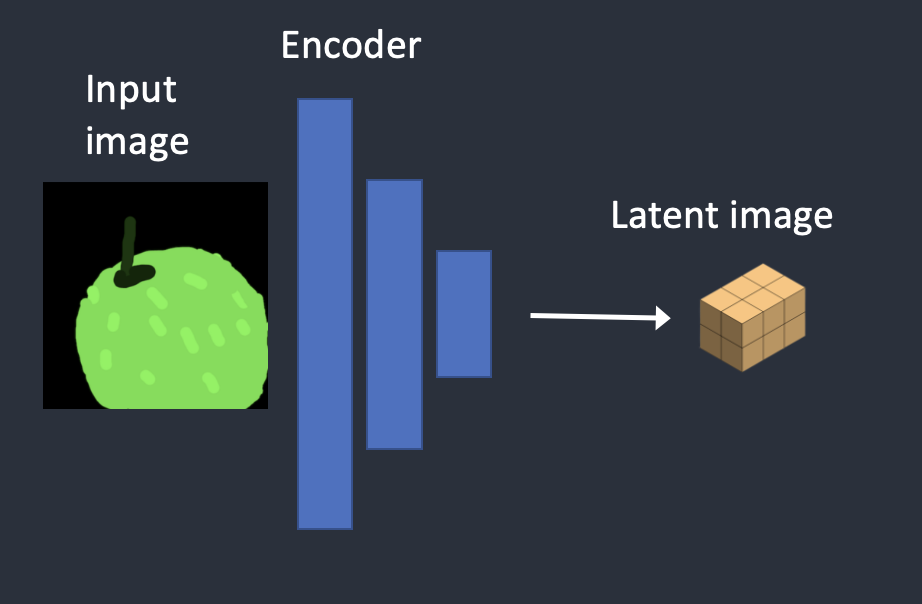
Step 2:
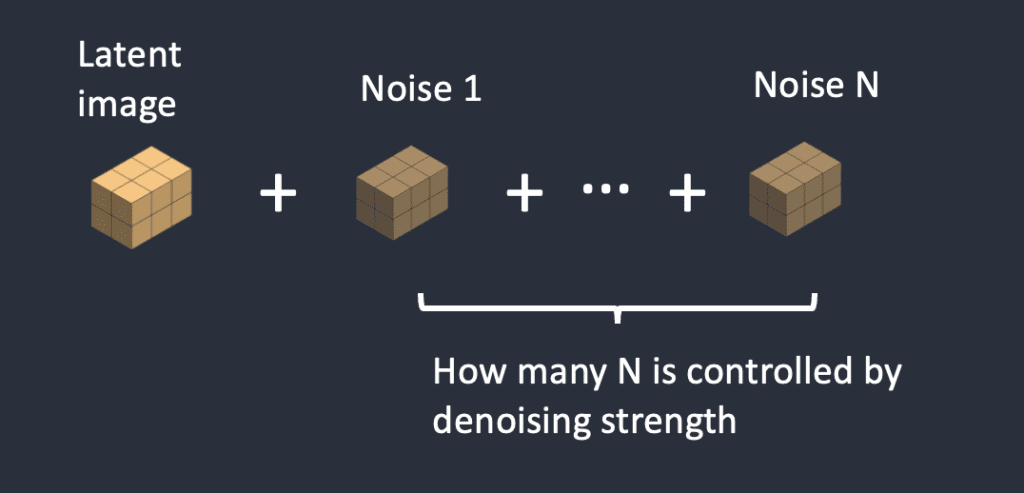
Nhiễu sẽ được thêm vào latent image. Denoising strength sẽ điều khiển bao nhiêu noise sẽ được thêm. Denoising strength có value từ 0 – 1, nếu bằng 0, không có nhiễu được thêm vào. Nếu strength bằng 1, thì maximum noise sẽ được thêm vào và latent image sẽ trở thành random tensor hoàn toàn.
Step 3:
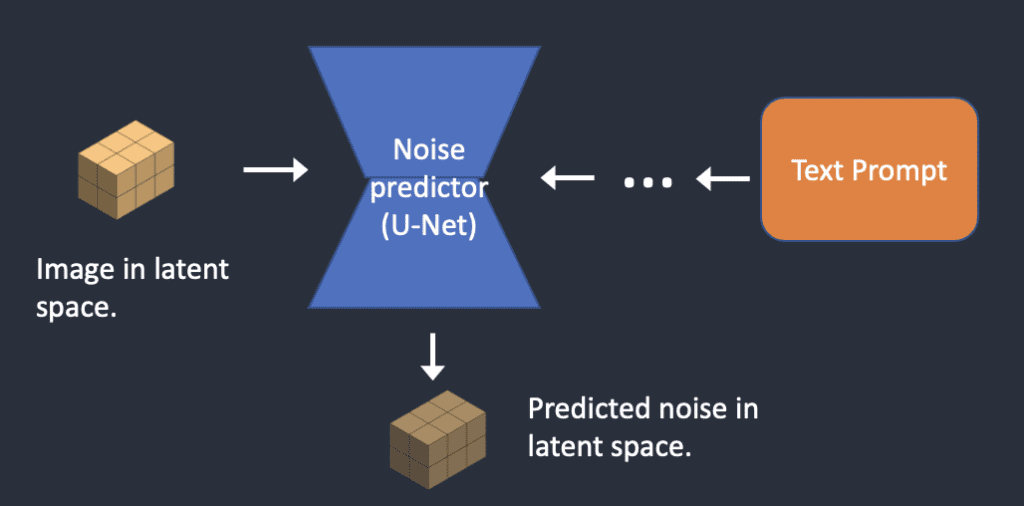
Noise predictor Unet sẽ lấy latent noise image và text prompt và predict noise
Step 4:
latent image mới = latent image – predicted noise
Step 5:
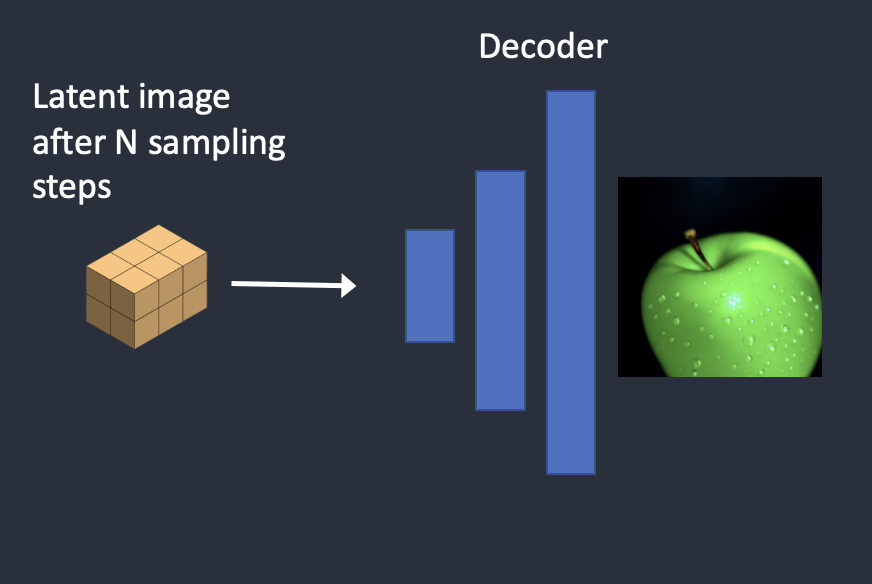
VAE model sẽ convert latent image thành pixel.
Nguồn: https://stable-diffusion-art.com/how-stable-diffusion-work/


