
In the digital age, data plays a crucial role in decision-making and analysis. To fully leverage the value from data, we need efficient data mining tools. Pandas is one of Python’s leading libraries, designed to handle large and complex datasets.
What is Pandas?
Pandas is a popular Python library that makes it easy to work with datasets. From analysis, cleaning, exploration, to data manipulation, Pandas provides everything you need to turn dry numbers into valuable information.
Developed by Wes McKinney in 2008, the name “Pandas” not only refers to “Panel Data” but also to “Python Data Analysis”—an optimal data analysis tool for data scientists and software developers.

Why Using Pandas?
Pandas allows you to analyze large datasets and draw conclusions based on statistical theories. It helps you “clean up” and explore messy datasets, making them more readable and meaningful.
This is an essential skill in Data Science – the field dedicated to studying how to store, use, and analyze data to extract useful information.
Installation
Before starting, you need to install Pandas. The simplest way to install Pandas is using pip:
pip install pandasPandas uses two main data structures: Series and DataFrame.
- Series: A one-dimensional array, like a column in a spreadsheet, that can contain any data type from integers to strings.
- DataFrame: Similar to a spreadsheet with multiple columns and rows, DataFrame is a combination of multiple Series. It’s a powerful tool for easy data manipulation and analysis.
Example of creating a DataFrame from a dictionary with Pandas:
import pandas as pd
data = {
'Name': ['An', 'Bình', 'Cường'],
'Age': [25, 30, 22],
'City': ['Hà Nội', 'Hồ Chí Minh', 'Đà Nẵng']
}
df = pd.DataFrame(data)
print(df)What Can You Do with Pandas?
With Pandas, you can uncover important insights from your data, such as:
- The relationship between two or more columns?
- What is the average value?
- What is the maximum value?
- What is the minimum value?
Pandas can also help you remove irrelevant rows or those containing incorrect values, such as empty or NULL values. This process is known as “data cleaning” and is crucial to ensure that your analyses are based on accurate and valuable data.
Pandas supports many different data formats, making it easy to convert between various types of data you work with.
- Read data from CSV:
df = pd.read_csv('data.csv')- Write data to CSV:
df.to_csv('data_out.csv', index=False)- Read data from JSON file:
pd.read_json("./data.json", lines=True)- Read data from SQL:
from sqlalchemy import create_engine
postgres_str = 'postgresql://admin:password@localhost:5432/db'
cnx = create_engine(postgres_str)
df = pandas.read_sql_query("""SELECT * FROM users""", con=cnx)Basic Data Manipulation with Pandas
Accessing and Filtering Data with Pandas
When working with data, accessing and filtering are very important. Pandas provides intuitive tools to quickly grasp key information from the data.
- Accessing a column:
age = df['Age']- Accessing multiple columns:
name_age = df[['Name', 'Age']]- Filtering data based on conditions:
adults = df[df['Age'] > 25]Data Manipulation: Adding, Removing, and Changing
Pandas not only lets you view data but also allows you to easily modify it.
- Adding a new column:
df['Age_After_10_Years'] = df['Age'] + 10- Removing a column:
df = df.drop('City', axis=1)- Changing values:
df.loc[0, 'Age'] = 26Cleaning Data
Missing data is a common challenge when working with real-world data. Pandas provides tools to clean data, ensuring that all your analyses are based on data that meets your standards.
- Checking for missing data:
df.isnull().sum()- Removing rows or columns with missing data:
df = df.dropna()- Filling missing values:
df['Age'] = df['Age'].fillna(df['Age'].mean())Illustration & Conclusion
Below are some visual examples of the results from executing data manipulation tasks using Pandas.

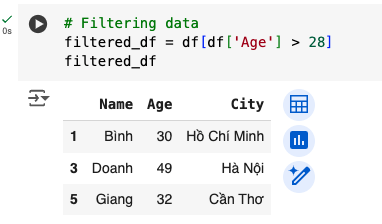
In summary, Pandas is not just a library but also a valuable tool for data scientists. Thanks to Pandas, data processing becomes simpler and more efficient.
I hope this article gives you an overview of the most basic techniques to get started with Pandas and Data Science. If you have any additional content or suggestions to contribute, please let me know by commenting below!

