
Apache Flink là một lựa chọn hàng đầu trong việc phát triển và triển khai nhiều loại ứng dụng khác nhau nhờ vào bộ tính năng phong phú. Các tính năng của Flink có thể xử lý dữ liệu dòng (data stream) và lô (data batch), quản lý trạng thái phức tạp, xử lý thời gian sự kiện (event-time processing) và đảm bảo về tính nhất quán cho trạng thái. Ngoài ra, Flink có thể triển khai trên các nhà cung cấp tài nguyên khác nhau như YARN và Kubernetes, nhưng cũng có thể triển khai như một cụm độc lập trên phần cứng bare-metal. Được thiết kế đảm bảo được tính sẵn có cao, Flink sẽ không gặp vấn đề khi một service bị lỗi. Flink đã vượt qua những bài test có khả năng mở rộng lên hàng ngàn chip lõi và hoạt động trên trạng thái nặng đến vài terabytes, cung cấp công suất xử lý cao và độ trễ thấp, và làm nền tảng cho một số ứng dụng đòi rất cao về việc xử lý dữ liệu dòng.
Ứng dụng trong Data Analytics
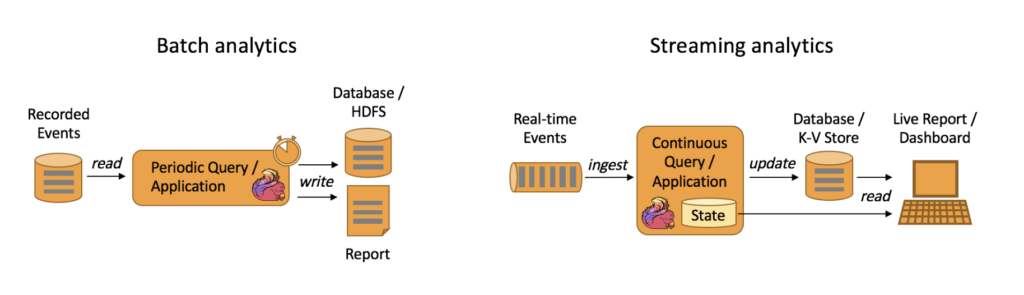
Ứng dụng Data Analytics trích xuất thông tin và hiểu biết từ dữ liệu thô. Theo phương pháp truyền thống, phân tích được thực hiện dưới dạng các truy vấn dữ liệu hàng loạt (batch queries) hoặc ứng dụng trên các tập dữ liệu giới hạn của các sự kiện được ghi lại. Để thêm dữ liệu mới nhất vào kết quả của phân tích, dữ liệu đó phải được thêm vào tập dữ liệu cũ, sau đó phân tích và truy vấn hoặc chạy lại. Kết quả của ứng dụng được ghi vào hệ thống lưu trữ hoặc được xuất ra dưới dạng báo cáo.
Với một hệ thống xử lý dòng dữ liệu phức tạp hơn, các phân tích cũng có thể được thực hiện theo kiểu thời gian thực. Thay vì đọc các tập dữ liệu hữu hạn, các truy vấn hoặc ứng dụng xử lý dòng thời gian thực nhận các luồng sự kiện thời gian thực (real time event streams) và liên tục tạo ra và cập nhật kết quả khi các sự kiện được nhận về. Kết quả được ghi vào một cơ sở dữ liệu bên ngoài hoặc được duy trì dưới dạng trạng thái nội bộ. Ứng dụng báo cáo thể đọc các kết quả mới nhất từ cơ sở dữ liệu hoặc truy vấn trực tiếp trạng thái nội bộ của ứng dụng.
Apache Flink hỗ trợ cả các ứng dụng phân tích dòng lẫn hàng loạt như được minh họa trong hình dưới đây.
(Nguồn: Apache Flink)
Các lợi ích của ứng dụng Data Analytics với dữ liệu dạng luồng
Các lợi ích của phân tích dòng liên tục so với phân tích dữ liệu theo lô không chỉ giới hạn ở thời gian trễ thấp hơn rất nhiều từ sự kiện đến kết quả phân tích nhờ loại bỏ được việc thực thi định kỳ. Ngược lại với các truy vấn theo lô, các truy vấn dòng không cần phải xử lý các ranh giới nhân tạo trong dữ liệu đầu vào mà được gây ra bởi việc nhập định kỳ và tính giới hạn của dữ liệu đầu vào.
Một khía cạnh khác là kiến trúc ứng dụng đơn giản hơn. Một đường ống phân tích hàng loạt bao gồm một số thành phần không phục thuộc lẫn nhau để lên lịch thực hiện nhập dữ liệu và thực thi truy vấn định kỳ. Việc vận hành trong pipeline như vậy là không đơn giản bởi vì khi một thành phần gặp lỗi thì sẽ ảnh hưởng đến các thành phần tiếp theo của pipeline. Ngược lại, một ứng dụng phân tích dữ liệu theo dòng trên một bộ xử lý dòng tinh vi như Flink bao gồm tất cả các bước từ nhập dữ liệu đến tính toán kết quả liên tục. Do đó, nó có thể dựa vào cơ chế phục hồi sự cố của bộ xử lý.
Một số ứng dụng tiêu biểu:
- Quality monitoring of Telco networks
- Analysis of product updates & experiment evaluation in mobile applications:
- Ad-hoc analysis of live data in consumer technology
Tài liệu tham khảo:

