
Để tăng tốc độ và độ chính xác tìm kiếm cho các hệ thống tìm kiếm thì một công cụ được sử dụng rộng rãi nhất hiện nay chính là Elasticsearch. Trong phần một này mình sẽ giới thiệu cách elasticsearch hoạt động và các thành phần logic của elasticsearch.
1. Elasticsearch là gì?
Cơ bản, Elasticsearch có thể được coi là một máy chủ có khả năng xử lý các yêu cầu JSON và trả về dữ liệu dưới dạng JSON.
Elasticsearch là một công cụ tìm kiếm và phân tích dữ liệu mở, phân tán, được xây dựng dựa trên Apache Lucene và phát triển bằng Java. Elasticsearch cho phép bạn lưu trữ, tìm kiếm và phân tích khối lượng lớn dữ liệu một cách nhanh chóng và gần như thời gian thực.
Nó có thể đáp ứng truy vấn nhanh chóng vì thay vì tìm kiếm trực tiếp trong văn bản, nó tìm kiếm trong một chỉ mục. Elasticsearch sử dụng cấu trúc dựa trên tài liệu thay vì bảng và lược đồ và đi kèm với API REST rộng rãi để lưu trữ và tìm kiếm dữ liệu.
2. Elasticsearch hoạt động như thế nào?
Cơ bản, Elasticsearch tổ chức dữ liệu thành các documents, là các đơn vị thông tin dựa trên JSON, đại diện cho các thực thể. Các tài liệu được nhóm vào các indices (chỉ mục), tương tự như cơ sở dữ liệu, dựa trên đặc điểm của chúng. Elasticsearch sử dụng chỉ mục đảo ngược, một cấu trúc dữ liệu ánh xạ từ ngữ từ đến vị trí tài liệu của chúng, để tìm kiếm hiệu quả. Kiến trúc phân tán(nodes/clusters) của Elasticsearch cho phép tìm kiếm và phân tích khối lượng dữ liệu lớn với hiệu suất gần như thời gian thực.
Để hiểu rõ hơn về cách Elasticsearch hoạt động, bây giờ mình sẽ giới thiệu các core concept của nó.
3. Các core concepts của Elasticsearch
3.1 Documents
Document là đơn vị cơ bản của thông tin có thể được lập chỉ mục trong Elasticsearch, được biểu diễn dưới dạng JSON. Bạn có thể coi một tài liệu giống như một hàng trong cơ sở dữ liệu quan hệ, đại diện cho một thực thể cụ thể – thứ bạn đang tìm kiếm.
Trong Elasticsearch, một document có thể là nhiều hơn chỉ là văn bản, nó có thể là bất kỳ dữ liệu có cấu trúc nào được mã hóa trong JSON. Dữ liệu đó có thể là số, chuỗi và ngày tháng. Mỗi document có một ID duy nhất và một loại dữ liệu cụ thể, mô tả loại thực thể mà tài liệu đại diện.
Ví dụ, một document có thể đại diện cho một bài viết bách khoa toàn thư hoặc các mục nhật ký từ một máy chủ web.
3.2 Indices
Một Indices (chỉ mục) là một tập hợp các tài liệu có đặc điểm tương tự. Chỉ mục là thực thể cấp cao nhất mà bạn có thể truy vấn trong Elasticsearch.
3.3 Inverted Index (Chỉ mục đảo ngược)
Một chỉ mục trong Elasticsearch thực chất là cái được gọi là chỉ mục đảo ngược, đây là cơ chế mà tất cả các công cụ tìm kiếm đều sử dụng. Đây là một cấu trúc dữ liệu lưu trữ ánh xạ từ nội dung, như từ ngữ hoặc số, đến vị trí của chúng trong một tài liệu hoặc một tập hợp các tài liệu.
Cơ bản, đây là một cấu trúc dữ liệu giống như bảng băm, hướng dẫn bạn từ một từ đến một tài liệu. Một chỉ mục đảo ngược không lưu trữ trực tiếp các chuỗi mà thay vào đó, nó chia mỗi tài liệu thành các thuật ngữ tìm kiếm riêng lẻ (tức là mỗi từ) rồi ánh xạ mỗi thuật ngữ tìm kiếm đó đến các tài liệu mà thuật ngữ đó xuất hiện.
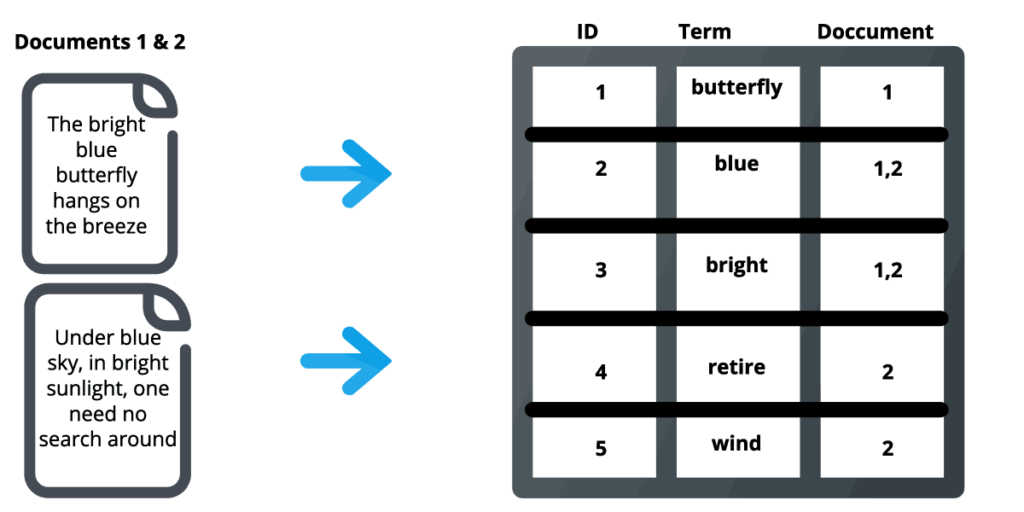
Trên đây là giới thiệu chung về Elastic search cách hoạt động và các khái niêm cốt lõi của nó. Ở phần tiếp theo mình sẽ tiếp tục giới thiệu các thành phần khác của Elastic search như Backend Components, kiến trúc phân tán..vv..


One Reply to “Elasticsearch – P1: Elasticsearch hoạt động ra sao?”