Giới thiệu
Đầu tiên PostgreSQL là một trong những hệ quản trị cơ sở dữ liệu quan hệ mã nguồn mở mạnh mẽ nhất hiện nay. Bài viết này sẽ giải thích chi tiết kiến trúc logic và vật lý của PostgreSQL, cách nó xử lý các truy vấn SQL.
Kiến trúc Logic
Phân cấp Logic của PostgreSQL
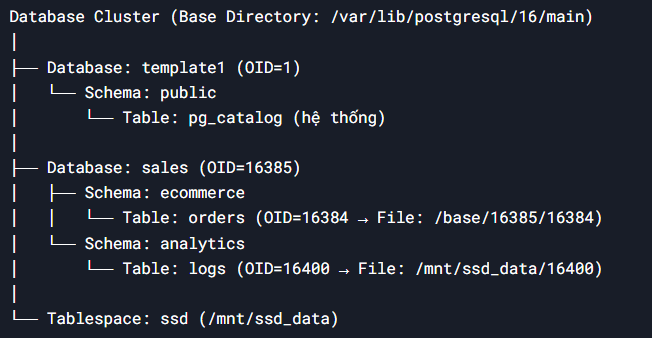
- Database Cluster:
- Một PostgreSQL server quản lý một Database Cluster duy nhất. Cluster là tập hợp các database, roles, tablespace và các cài đặt chung
- Ví dụ: Khi cài đặt PostgreSQL, bạn tạo một cluster mặc định ở thư mục
/var/lib/postgresql/16/main. Mọi lệnhCREATE DATABASEsau đó đều thuộc cluster nàySHOW data_directory; --Kết quả: /var/lib/postgresql/16/main
- Database:
- Một cluster chứa nhiều database, mỗi database độc lập về dữ liệu và metadata. Các database không thể giao tiếp trực tiếp với nhau. Để truy vấn dữ liệu giữa các database phải dùng Foreign Data Wrapper (FDM)
- Ví dụ tạo database sales và hr trong cùng một cluster:
CREATE DATABASE sales;CREATE DATABASE hr;
- Schema
- Mỗi database chứa một hoặc nhiều schema, đóng vai trò như “không gian tên” để nhóm các object (tabke, index, function) và quản lý quyền truy cập
- Ví dụ: tạo schema ecommerce và analytics trong database sales
\c sales -- Kết nối vào database sales
CREATE SCHEMA ecommerce;
CREATE SCHEMA analytics;
- Object
- Các đối tượng như table, index, view, sequence được lưu trữ trong schema. Mỗi ọnect có Object Identifier (OID) duy nhất để quản lý nội bộ
- Ví dụ: Tạo table orders trong schema ecommerce:
CREATE TABLE ecommerce.orders (
order_id SERIAL PRIMARY KEY,
user_id INT,
amount NUMERIC
); - Kiểm tra OID của table:
SELECT oid, relname FROM pg_class WHERE relname = 'orders';
-- Kết quả: OID = 16384
Kiến trúc Vật Lý
Kiến trúc vật lý mô tả cách dữ liệu được lưu trữ trên disk. Mọi thành phần logic đều được ánh xạ đến file hoặc thư mục cụ thể
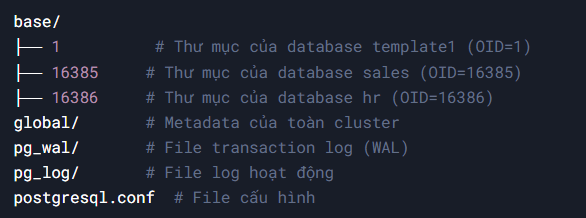
- Base Directory
- Thư mục gốc chứa toàn bộ dữ liệu của cluster
- Ví dụ:
/var/lib/postgresql/16/main - Cấu trúc thư mục
- Các file quan trọng
- pg_hba.conf:
- Xác định quyền kết nối đến PostgreSQL
- Ví dụ: Cho phép user admin kết nối từ IP 192.168.1.0/24:
host sales admin 192.168.1.0/24 md5
- postgresql.conf
- Cấu hình tham số server
- Ví dụ: Đổi port mặc định port = 5433
- PG_VERSION
- Lưu phiên bản PostgreSQL
- postmaster.pid
- Lưu PID của tiến trình PostgreSQL
- pg_hba.conf:
- Tablespace
- Tablespace cho phép lưu dữ liệu trên các ổ đĩa khác nhau để tối ưu hiệu năng
- Ví dụ: Tạo tablespace trên SSD và lưu table vào đó
CREATE TABLESPACE ssd LOCATION '/mnt/ssd_data';
CREATE TABLE analytics.logs ( log_id SERIAL, message TEXT ) TABLESPACE ssd;
- Lưu trữ table và index
- Mỗi table/index được lưu thành file vật lý dưới tên OID
- Ví dụ
- Table
orderstrong databasesalescóOID=16384-> File:/base/16385/16384 - Index trên cột
user_idcóOID=16387-> File:/base/16385/16387
- Table
Chiến lược thực thi SQL trong PostgreSQL
PostgreSQL sử dụng một quy trình tối ưu hóa và thực thi câu lệnh SQL rất mạnh mẽ, bao gồm các bước chính sau:
- Parsing (Phân tích cú pháp)
- PostgreSQL kiểm tra cú pháp câu lệnh SQL và chuyển đổi nó thành một cây cú pháp (parse tree).
- Ví dụ:
SELECT * FROM orders WHERE amount > 1000;- Parse tree sẽ bao gồm các node như
SELECT,FROM,WHERE, và điều kiệnamount > 1000.
- Parse tree sẽ bao gồm các node như
- Transformation (Chuyển đổi)
- Parse tree được chuyển đổi thành một cây truy vấn (query tree), bao gồm các toán tử và mối quan hệ giữa chúng.
- Ví dụ:
Query tree cho câu lệnh trên sẽ bao gồmSeq Scantrên bảngordersFiltervới điều kiệnamount > 1000.
- Optimization (Tối ưu hóa)
- PostgreSQL sử dụng Cost-Based Optimizer (CBO) để chọn execution plan tối ưu nhất dựa trên các yếu tố như CPU, I/O, và memory.
- Các phương pháp tối ưu hóa bao gồm:
- Index Scan: Sử dụng index để tìm kiếm nhanh.
- Hash Join: Kết hợp hai bảng bằng cách tạo hash table.
- Merge Join: Kết hợp hai bảng đã được sắp xếp.
- Nested Loop: Duyệt qua từng hàng của bảng này và so khớp với bảng kia.
- Ví dụ:
- SQL:
EXPLAIN SELECT * FROM orders JOIN customers ON orders.customer_id = customers.id WHERE orders.amount > 1000; - Kết quả:
- SQL:
Hash Join (cost=100.00..200.00 rows=5000 width=64)
Hash Cond: (orders.customer_id = customers.id)
-> Seq Scan on orders (cost=0.00..150.00 rows=5000 width=32)
Filter: (amount > 1000)
-> Hash (cost=80.00..80.00 rows=2000 width=32)
-> Seq Scan on customers (cost=0.00..80.00 rows=2000 width=32)- Execution (Thực thi)
- Execution engine thực thi từng node trong execution plan.
- Ví dụ
- Thực hiện
Seq Scantrên bảngordersvà lọc các hàng thỏa mãnamount > 1000 - Tạo hash table từ bảng
customersvà thực hiệnHash Joinvới kết quả từorders
- Thực hiện
So sánh thực thi câu lệnh phức tạp giữa PostgreSQL và MySQL
Ví dụ 1: Truy vấn với JOIN và Subquery
Câu lệnh SQL
SELECT c.name, o.total
FROM customers c
JOIN orders o ON c.id = o.customer_id
WHERE o.total > (SELECT AVG(total) FROM orders);- PostgreSQL:
- Sử dụng Hash Join và Subquery Scan:
- Execution Plan:
Hash Join (cost=150.00..300.00 rows=5000 width=64)
Hash Cond: (c.id = o.customer_id)
-> Seq Scan on customers c (cost=0.00..80.00 rows=2000 width=32)
-> Hash (cost=100.00..100.00 rows=5000 width=32)
-> Seq Scan on orders o (cost=0.00..100.00 rows=5000 width=32)
Filter: (total > (subquery))- MySQL:
- Sử dụng Nested Loop Join và thực thi subquery riêng biệt
- Execution Plan:
-> Nested Loop Join (cost=200.00..400.00 rows=5000)
-> Seq Scan on customers c (cost=0.00..80.00 rows=2000)
-> Filter: (o.total > (subquery)) (cost=0.00..0.00 rows=1)
-> Seq Scan on orders o (cost=0.00..100.00 rows=5000)Nhận xét: PostgreSQL tối ưu hóa tốt hơn với Hash Join, trong khi MySQL thường sử dụng Nested Loop Join, dẫn đến hiệu năng kém hơn với dữ liệu lớn.
Ví dụ 2: Truy vấn với Window Functions
Câu lệnh:
SELECT name, total, RANK() OVER (ORDER BY total DESC)
FROM orders;- PostgreSQL:
- Hỗ trợ sẵn Window Functions và tối ưu hóa tốt.
- Execution Plan
WindowAgg (cost=100.00..150.00 rows=5000 width=64)
-> Sort (cost=100.00..110.00 rows=5000 width=32)
Sort Key: total DESC
-> Seq Scan on orders (cost=0.00..80.00 rows=5000 width=32)- MySQL
- Hỗ trợ Window Functions từ phiên bản 8.0+, nhưng hiệu năng kém hơn.
- Execution Plan
-> WindowAgg (cost=200.00..300.00 rows=5000)
-> Sort (cost=200.00..220.00 rows=5000)
Sort Key: total DESC
-> Seq Scan on orders (cost=0.00..100.00 rows=5000)Nhận xét: PostgreSQL xử lý Window Functions nhanh hơn nhờ tối ưu hóa sắp xếp và phân nhóm.
Ví dụ 3: Insert 1 triệu records
Câu lệnh:
INSERT INTO logs (message)
SELECT md5(random()::text)
FROM generate_series(1, 1000000);- PostgreSQL
- Sử dụng WAL (Write-Ahead Logging) để đảm bảo tính toàn vẹn dữ liệu.
- Thời gian: ~45 giây.
- MySQL
- Sử dụng InnoDB với transaction và redo log.
- Thời gian: ~30 giây.
Nhận xét: PostgreSQL chậm hơn khi insert nhiều records do cơ chế WAL. MySQL nhanh hơn trong trường hợp này nhờ cơ chế transaction linh hoạt.
Kết Luận
PostgreSQL là một hệ quản trị cơ sở dữ liệu mạnh mẽ với nhiều ưu điểm nổi bật. Trước hết, PostgreSQL cung cấp khả năng xử lý truy vấn phức tạp vượt trội nhờ Cost-Based Optimizer thông minh. Bên cạnh đó, hệ thống còn đảm bảo tính toàn vẹn dữ liệu cao thông qua cơ chế MVCC và WAL.
Tài liệu tham khảo: