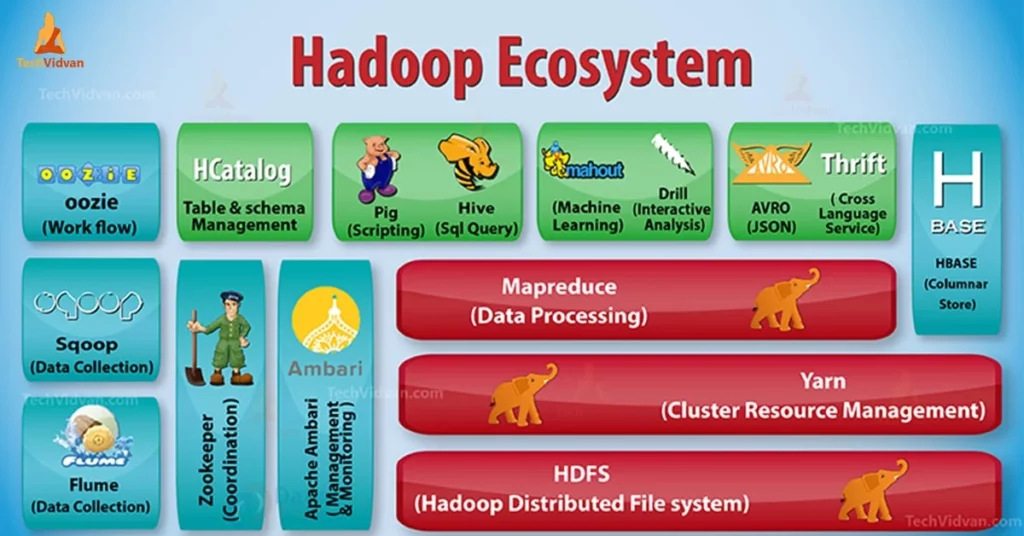
Giới thiệu về Hadoop
Hadoop là một Apache framework nguồn mở viết bằng Java cho phép phát triển các ứng dụng phân tán có cường độ dữ liệu lớn một cách miễn phí. Nó được thiết kế để mở rộng quy mô từ một máy chủ đơn sang hàng ngàn máy tính khác có tính toán và lưu trữ cục bộ (local computation and storage).
Hadoop được phát triển dựa trên ý tưởng từ các công bố của Google về mô hình Map-Reduce và hệ thống file phân tán Google File System (GFS). Và có cung cấp cho chúng ta một môi trường song song để thực thi các tác vụ Map-Reduce.
Nhờ có cơ chế streaming mà Hadoop có thể phát triển trên các ứng dụng phân tán bằng cả java lẫn một số ngôn ngữ lập trình khác như C++, Python, Pearl,…
Kiến trúc của Hadoop
Kiến trúc Hadoop gồm có ba lớp chính:
- HDFS (Hadoop Distributed File System)
- Map-Reduce
- Yarn
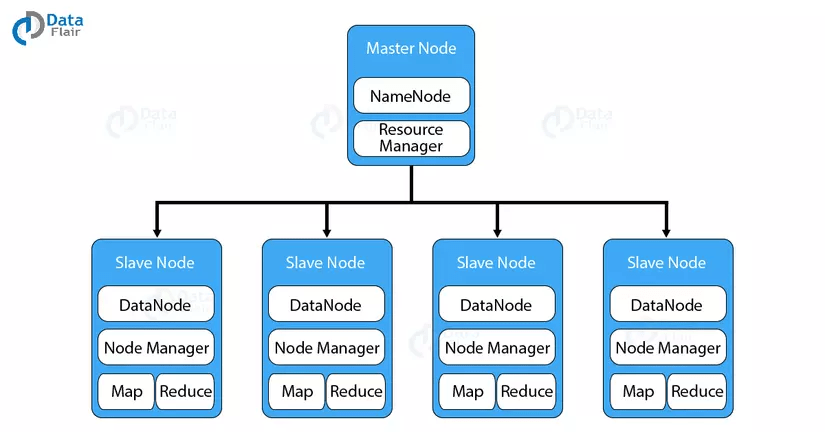
1. HDFS
HDFS là hệ thống file phân tán, cung cấp khả năng lưu trữ dữ liệu khổng lồ và tính năng tối ưu hoá việc sử dụng băng thông giữa các node. HDFS có thể được sử dụng để chạy trên một cluster lớn với hàng chục ngàn node.
HDFS có kiến trúc master-slave. Một cluster sẽ bao gồm một master node và nhiều slave node.
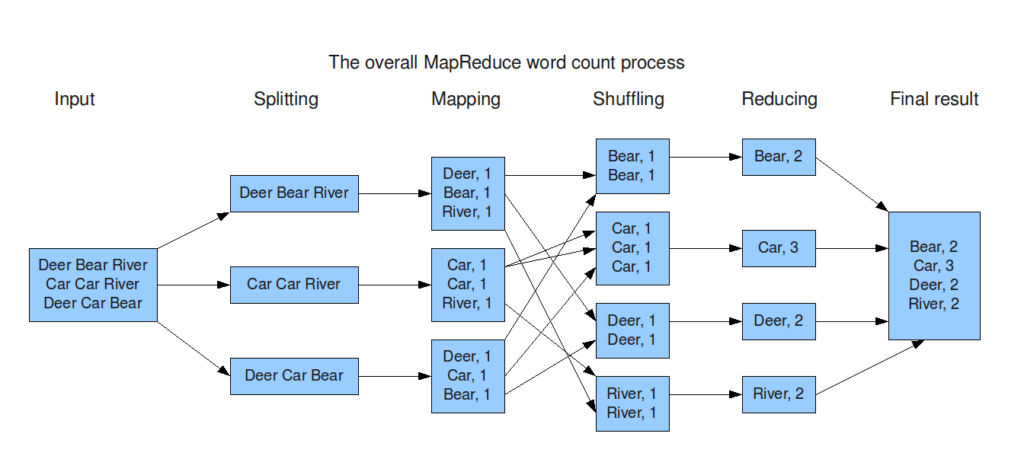
2. Map Reduce
Map-Reduce là một framework dùng để viết các ứng dụng xử lý song song một lượng lớn dữ liệu có khả năng chịu lỗi cao xuyên suốt hàng ngàn cluster(cụm) máy tính
Map-Reduce thực hiện 2 chức năng chính đó là Map và Reduce
- Map: Sẽ thực hiện đầu tiên, có chức năng tải, phân tích dữ liệu đầu vào và được chuyển đổi thành tập dữ liệu theo cặp key/value
- Reduce: Sẽ nhận kết quả đầu ra từ tác vụ Map, kết hợp dữ liệu lại với nhau thành tập dữ liệu nhỏ hơn
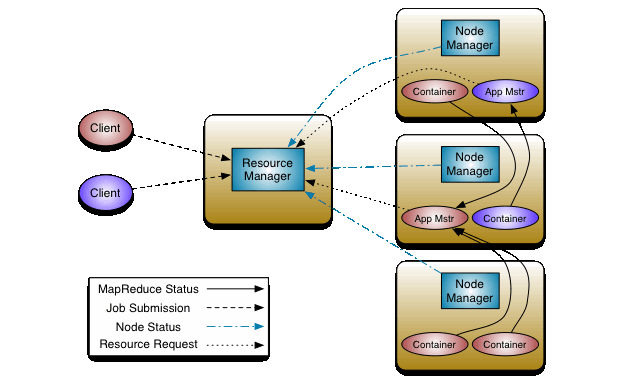
3. Yarn
YARN (Yet-Another-Resource-Negotiator) là một framework hỗ trợ phát triển ứng dụng phân tán YARN cung cấp daemons và APIs cần thiết cho việc phát triển ứng dụng phân tán, đồng thời xử lý và lập lịch sử dụng tài nguyên tính toán (CPU hay memory) cũng như giám sát quá trình thực thi các ứng dụng đó.
Bên trong YARN, chúng ta có hai trình quản lý ResourceManager và NodeManage
- ResourceManager: Quản lý toàn bộ tài nguyên tính toán của cluster.
- NodeManger: Giám sát việc sử dụng tài nguyên của container và báo cáo với ResourceManger. Các tài nguyên ở đây là CPU, memory, disk, network,…
Chúng ta có thể mở rộng YARN ngoài một vài nghìn node thông qua tính năng YARN Federation.
Lịch sử phát triển của Hadoop
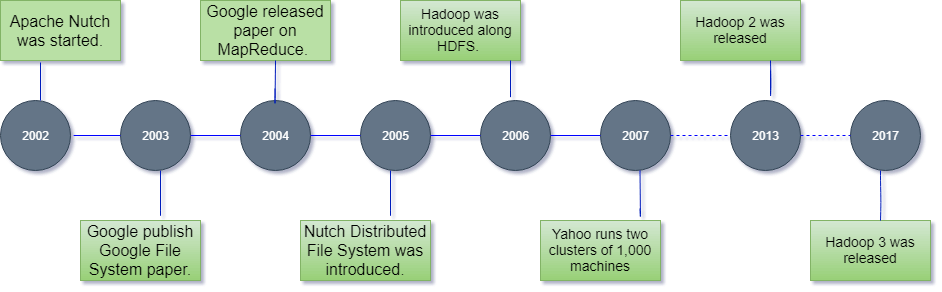
| Năm | Sự kiện |
|---|---|
| 2003 | Google xuất bản tài liệu về Google File System (GFS). |
| 2004 | Google xuất bản tài liệu về Map Reduce. |
| 2006 | Hadoop được giới thiệu, Hadoop 0.1.0 được phát hành. |
| 2007 | HBase được đưa vào Hadoop. |
| 2008 | YARN JIRA được triển khai. Hadoop trở thành hệ thống nhanh nhất để xử lý 1 terabyte dữ liệu trên cluster 900 node trong vòng 209 giây. Cloudera được thành lập, trở thành nhà phân phối Hadoop. |
| 2009 | Hadoop đủ khả năng vận hành 1 petabyte. MapReduce và HDFS được tách thành hai dự án riêng biệt. |
| 2010 | Hadoop thêm hỗ trợ cho Kerberos. Hadoop đã có thể vận hành 4.000 nút với 40 petabyte. Apache Hive và Pig được phát hành. |
| 2011 | Apache Zookeeper |
| 2012 | Apache Hadoop 1.0 |
| 2013 | Apache Hadoop 2.2 |
| 2014 | Apache Hadoop 2.6 |
| 2015 | Apache Hadoop 2.7 |
| 2017 | Apache Hadoop 3.0 |
| 2018 | Apache Hadoop 3.1 |


