Big Data là gì?
Big Data (Dữ liệu lớn) là thuật ngữ dùng để mô tả một lượng dữ liệu khổng lồ và phức tạp đến mức các công cụ quản lý dữ liệu truyền thống không có khả năng thu thập, quản lý và xử lý dữ liệu trong một khoảng thời gian hợp lý.
Big Data không chỉ đề cập đến kích thước của dữ liệu mà còn bao gồm tốc độ, sự đa dạng và tính xác thực của dữ liệu.
Phân loại Big Data
Dựa trên cấu trúc dữ liệu, Big Data có thể được phân loại thành 3 loại chính:
Dữ liệu có cấu trúc
Đây là loại dữ liệu dễ dàng nhất để quản lý và tìm kiếm. Dữ liệu có cấu trúc được lưu trữ và xử lý ở các định dạng cố định, có thể dễ dàng truy cập và xử lý bằng các công cụ như MySQL, Oracle, SQL Server. Ví dụ: thông tin khách hàng, dữ liệu giao dịch, dữ liệu tài chính,…
Dữ liệu bán cấu trúc
Dữ liệu này có một số cấu trúc nhất định nhưng không hoàn toàn tuân theo định dạng cố định. Chúng được xử lý bằng các công cụ truyền thống sau khi được xử lý sơ bộ.
Ví dụ: email HTML, XML, JSON,…
Dữ liệu phi cấu trúc
Dữ liệu này không có định dạng cố định và khó khăn trong việc xử lý bằng các công cụ truyền thống. Chúng chiếm phần lớn khối lượng dữ liệu Big Data.
Ví dụ: email, tin nhắn, hình ảnh, video, âm thanh, dữ liệu cảm biến, nhật ký,…
7V – 7 đặc tính của Big Data
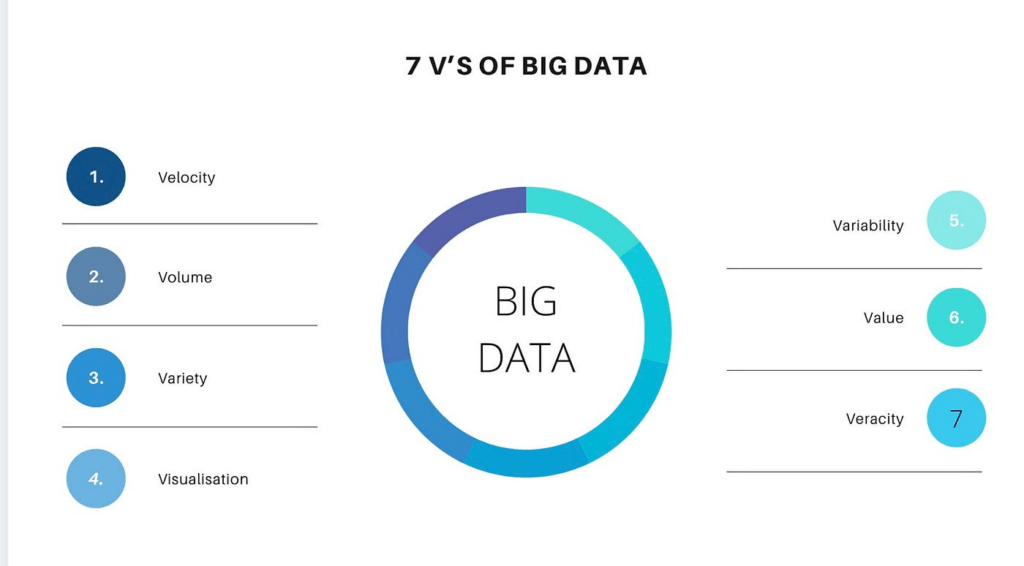
1. Volume (Khối lượng)
Khối lượng dữ liệu trong Big Data rất lớn, thường là hàng terabyte (TB), petabyte (PB) hoặc thậm chí exabyte (EB). Khối lượng dữ liệu khổng lồ này đến từ nhiều nguồn khác nhau như mạng xã hội, cảm biến, giao dịch thương mại điện tử và các thiết bị IoT. Việc xử lý và lưu trữ lượng dữ liệu lớn đòi hỏi các công nghệ và cơ sở hạ tầng đặc biệt.
2. Velocity (Tốc độ)
Tốc độ xử lý và truyền tải dữ liệu là một yếu tố quan trọng của Big Data. Dữ liệu được tạo ra và truyền tải với tốc độ rất nhanh từ các nguồn trực tuyến, mạng xã hội, cảm biến và hệ thống giao dịch. Khả năng xử lý dữ liệu theo thời gian thực hoặc gần thời gian thực là một yêu cầu quan trọng để khai thác giá trị từ Big Data.
3. Variety (Đa dạng)
Dữ liệu trong Big Data đến từ nhiều nguồn khác nhau và ở nhiều định dạng khác nhau, bao gồm dữ liệu có cấu trúc (structured), dữ liệu bán cấu trúc (semi-structured) và dữ liệu phi cấu trúc (unstructured).
Các dạng dữ liệu bao gồm văn bản, hình ảnh, video, âm thanh, log files, và nhiều loại dữ liệu khác. Sự đa dạng này đòi hỏi các kỹ thuật và công cụ đặc biệt để phân tích và xử lý.
4. Veracity (Tính xác thực)
Tính xác thực của dữ liệu đề cập đến chất lượng và độ tin cậy của dữ liệu. Dữ liệu từ nhiều nguồn khác nhau có thể không nhất quán hoặc không chính xác. Việc đảm bảo tính xác thực của dữ liệu là quan trọng để có được kết quả phân tích đáng tin cậy.
5. Value (Giá trị)
Giá trị là mục tiêu cuối cùng của việc khai thác Big Data.
Dữ liệu lớn có thể mang lại những hiểu biết và thông tin giá trị giúp các tổ chức và doanh nghiệp đưa ra các quyết định chiến lược, tối ưu hóa hoạt động và tạo ra lợi thế cạnh tranh. Việc khai thác giá trị từ Big Data đòi hỏi các công cụ và kỹ thuật phân tích mạnh mẽ.
6. Variability (Biến động)
Biến động đề cập đến sự không nhất quán của dữ liệu. Lưu lượng dữ liệu có thể thay đổi đáng kể theo thời gian, làm cho việc quản lý và phân tích dữ liệu trở nên phức tạp hơn. Việc xử lý các khối lượng dữ liệu biến động đòi hỏi các hệ thống linh hoạt và có khả năng mở rộng.
7. Visualization (Trực quan hóa)
Trực quan hóa dữ liệu là khả năng trình bày dữ liệu một cách trực quan và dễ hiểu. Việc sử dụng các công cụ trực quan hóa giúp biến dữ liệu phức tạp thành các biểu đồ, đồ thị và báo cáo dễ hiểu, hỗ trợ quá trình ra quyết định.
Trực quan hóa dữ liệu là một phần quan trọng của Big Data, giúp các nhà phân tích và người ra quyết định hiểu rõ hơn về dữ liệu và các kết quả phân tích.
Một số công nghệ dành cho Big Data
Hệ sinh thái Hadoop
Hadoop là một Apache framework mã nguồn mở được viết bằng Java, cho phép xử lý phân tán (distributed processing) các tập dữ liệu lớn trên các cụm máy tính (clusters of computers) thông qua mô hình lập trình đơn giản.
Hadoop được thiết kế để mở rộng quy mô từ một máy chủ đơn sang hàng ngàn máy tính khác có tính toán và lưu trữ cục bộ (local computation and storage).
Hadoop bao gồm nhiều nhánh, có thể kể đế:
- Hadoop Common
- Hadoop Distributed File System
- Hadoop YARN
- Hadoop MapReduce
Apache Spark
Spark là một framework mã nguồn mở tính toán cụm, được phát triển sơ khởi vào năm 2009 bởi AMPLab. Sau này, Spark đã được sở hữu bởi Apache Software Foundation vào năm 2013 và được phát triển cho đến nay.
Tốc độ xử lý của Spark có được do việc tính toán được thực hiện cùng lúc trên nhiều máy khác nhau. Đồng thời việc tính toán được thực hiện ở bộ nhớ trong (in-memories) hay thực hiện hoàn toàn trên RAM.
Spark cung cấp các phương thức hỗ trợ đối với:
- Java
- Scala
- Python (đặc biệt là Anaconda Python distro)
- R (R đặc biệt phù hợp với big data)
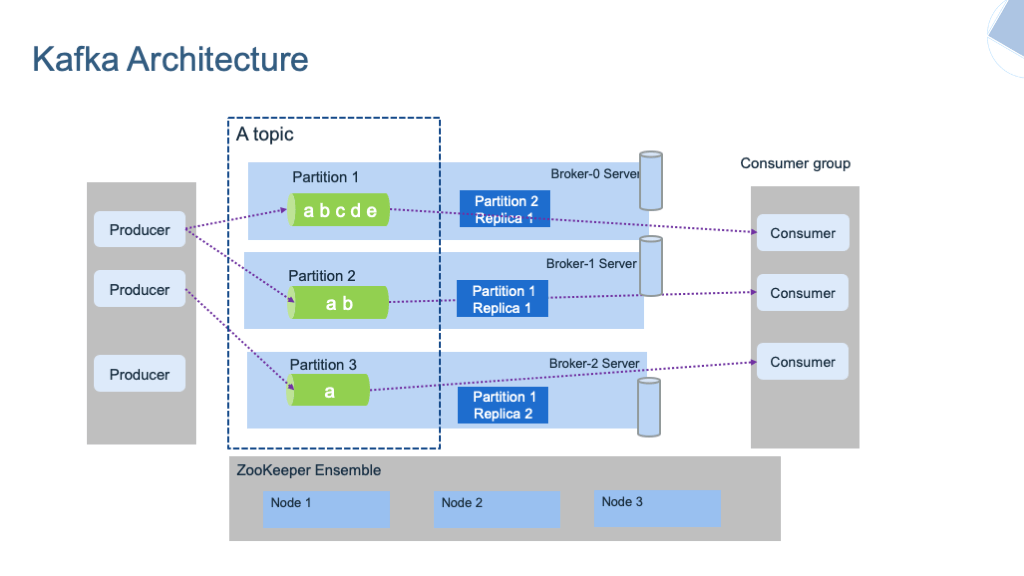
Apache Kafka
Apache Kafka là một kho dữ liệu phân tán được tối ưu hóa để thu nạp và xử lý dữ liệu truyền phát theo thời gian thực. Dữ liệu truyền phát là dữ liệu được tạo ra liên tục từ hàng nghìn nguồn dữ liệu khác nhau, các nguồn này thường gửi các bản ghi dữ liệu đồng thời.
Nền tảng truyền phát cần phải xử lý luồng dữ liệu liên tục này và xử lý dữ liệu theo trình tự và tăng dần.
Kafka cung cấp ba chức năng chính cho người dùng:
- Xuất bản và đăng ký các luồng bản ghi
- Lưu trữ hiệu quả các luồng bản ghi theo thứ tự tạo bản ghi
- Xử lý các luồng bản ghi trong thời gian thực