
Tất cả chúng ta đều đã tạo các trang web CRUD cơ bản. Nhìn lại các dự án cá nhân của mình, tôi thấy mình vẫn ổn khi không cần phân trang. Tại sao như vậy? Bởi vì phạm vi của dự án rất nhỏ. Nhỏ đến mức thậm chí việc tìm nạp tất cả các hàng cùng một lúc cũng chẳng có tác dụng gì.
Khi làm việc với một tập dữ liệu lớn, việc phân trang là điều bắt buộc phải có. Bạn hẳn đã nhận thấy điều này tại nơi làm việc hoặc trong cơ sở mã của bất kỳ dự án nguồn mở có quy mô vừa phải nào.
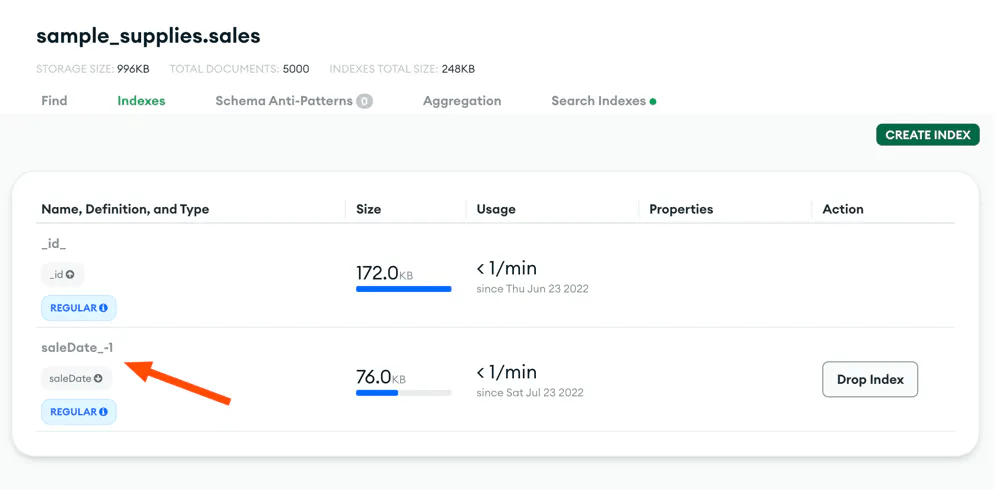
Thiết lập MongoDB Atlas
Chúng ta sẽ sử dụng MongoDB Atlas cho bài viết này. Tạo đã tạo index cho trường saleDate , chúng ta sẽ cần dùng đến nó
Tại sao sử dụng phân trang ở server-side?
Hãy xem cách phân trang phía client-side hoạt động và hiểu vì sao phân trang phía server-side tốt hơn.
Như tên gọi, phân trang phía client-side xảy ra ở phía client-side. Tất cả dữ liệu được lấy về một lần và các thành phần giao diện người dùng hiển thị một phần lớn dữ liệu đó thành các trang.
Chúng ta đã từng xác định trước đó rằng việc lấy tất cả các hàng của một bảng một lần không phải lúc nào cũng là ý tưởng tốt. Ngay cả khi phân trang phía client-side gần như ngay lập tức sau khi bạn có dữ liệu, vấn đề cơ bản vẫn tồn tại.
Phân trang phía client-side không phải là một lựa chọn khả thi nếu tập dữ liệu lớn hoặc có tiềm năng là vậy. Hãy chuyển sang phân trang phía server-side.
Cách triển khai phân ở server-side
Chúng ta sẽ xem hai cách để thực hiện phân trang trong API của bạn bằng Express:
- Offset based pagination sử dụng một kết hợp của offset (hoặc skip trong MongoDB) và limit để lấy các phần dữ liệu.
- Cursor based pagination không sử dụng offset mà thay vào đó sử dụng một con trỏ để theo dõi các lần lặp và di chuyển theo chiều tiến.
Sử dụng offset based pagination
Offset based pagination thực hiện phân trang phía máy chủ là một cách rõ ràng và có ý nghĩa. Đây là công thức hoàn hảo để được áp dụng rộng rãi. Nó chỉ vô hại cho đến khi độ trễ tìm nạp dữ liệu ở mức hợp lý. Mở rộng với tập dữ liệu của bạn và nó sẽ là một câu chuyện hoàn toàn khác.
Dưới đây là bản chất của cách thực hiện phân trang phía máy chủ sử dụng offset & limit:
db.Item.find()
.offset(offsetValue)
.limit(limitValue);Các vấn đề khi triển khai điều trên
Lý do khiến cách tiếp cận dựa trên offset chậm đáng kể là do nó tìm nạp nhiều dữ liệu hơn mức cần thiết.
Khi làm việc với phân trang dựa trên offset, nó sẽ tìm nạp tất cả các hàng cho đến hàng mong muốn.
Cơ sở dữ liệu sẽ tìm nạp tài liệu offset + limit ngay cả khi bạn chỉ cần tài liệu giới hạn sau offset.
Đây là kết quả giải thích để tìm nạp 20 tài liệu cuối cùng từ bộ sưu tập chứa tổng cộng 5000 tài liệu.
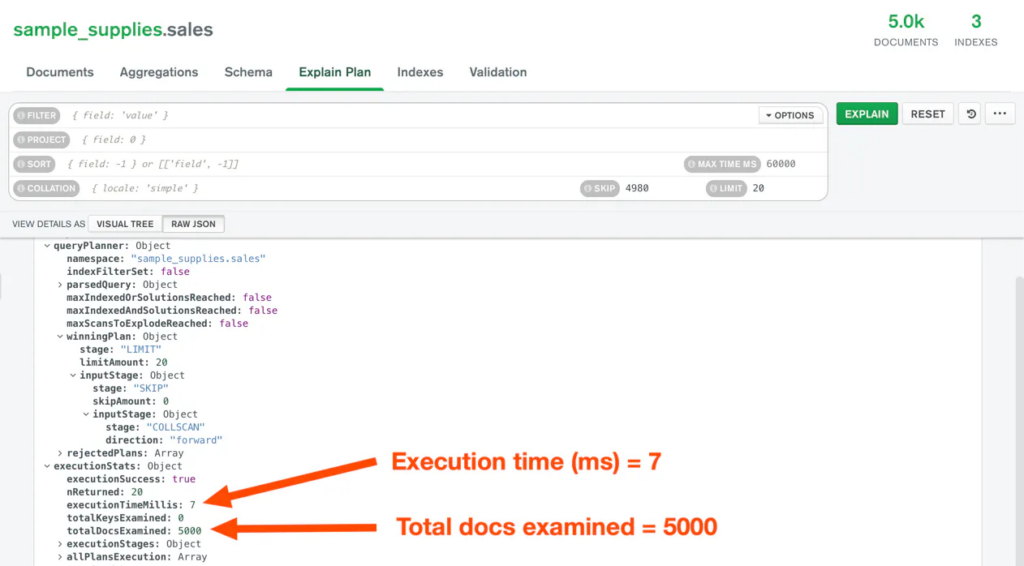
Điều này trở nên tồi tệ hơn với số lượng tài liệu ngày càng tăng. Người dùng của bạn sẽ nghĩ rằng trang web của bạn có thể bị hỏng và họ sẽ thoát ra.
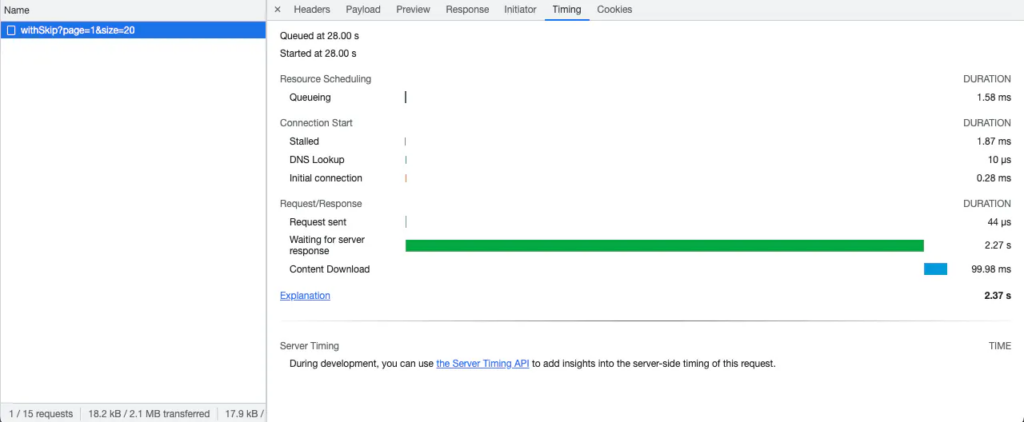
Đây là lượng thời gian cần thiết để chỉ tìm nạp 20 tài liệu từ bộ sưu tập chứa tổng cộng 5000 tài liệu:
Một cách tiếp cận tốt hơn để phân trang phía máy chủ
Chúng ta đã xác định rằng việc sử dụng offset sẽ không tốt cho việc phân trang xét về mặt hiệu suất. Hãy nhìn vào giải pháp thay thế.
Chúng ta cần một cách để xử lý dữ liệu theo một thứ tự cụ thể và có một con trỏ để lưu trữ điểm tham chiếu khi tìm nạp dữ liệu được phân trang. Chúng ta cần một cách để tìm kiếm dữ liệu.
Để đảm bảo chúng tôi có dữ liệu theo thứ tự cụ thể và có thể dự đoán được, chúng ta có thể sắp xếp dữ liệu dựa trên bất kỳ cột nào. Cột phải lưu trữ các giá trị duy nhất để sắp xếp nhất quán. Do đó, timestamp thường là cột tốt để làm mục tiêu. Không bao giờ sắp xếp theo names, city, hoặc bất kỳ trường nào khác có thể có giá trị trùng lặp.
Sau khi được sắp xếp, vấn đề chỉ là tìm nạp dữ liệu theo khối X (giả sử là 20) và lưu dấu thời gian của tài liệu cuối cùng bạn đã tìm nạp. Nó sẽ được sử dụng để tìm nạp trang thứ hai bằng mệnh đề WHERE.
router.get("/withoutSkip", async (req, res) => {
const maxTriggerDate = req.query.date;
const sales = await Sales.find(
{ saleDate: { $lt: maxTriggerDate } },
{},
{ limit: 20 }
);
res.json({
data: sales,
error: false,
message: "Sales data fetched successfully",
totalPages: 1,
});
});Nhìn vào kết quả, rõ ràng tại sao phương pháp này lại nhanh hơn:
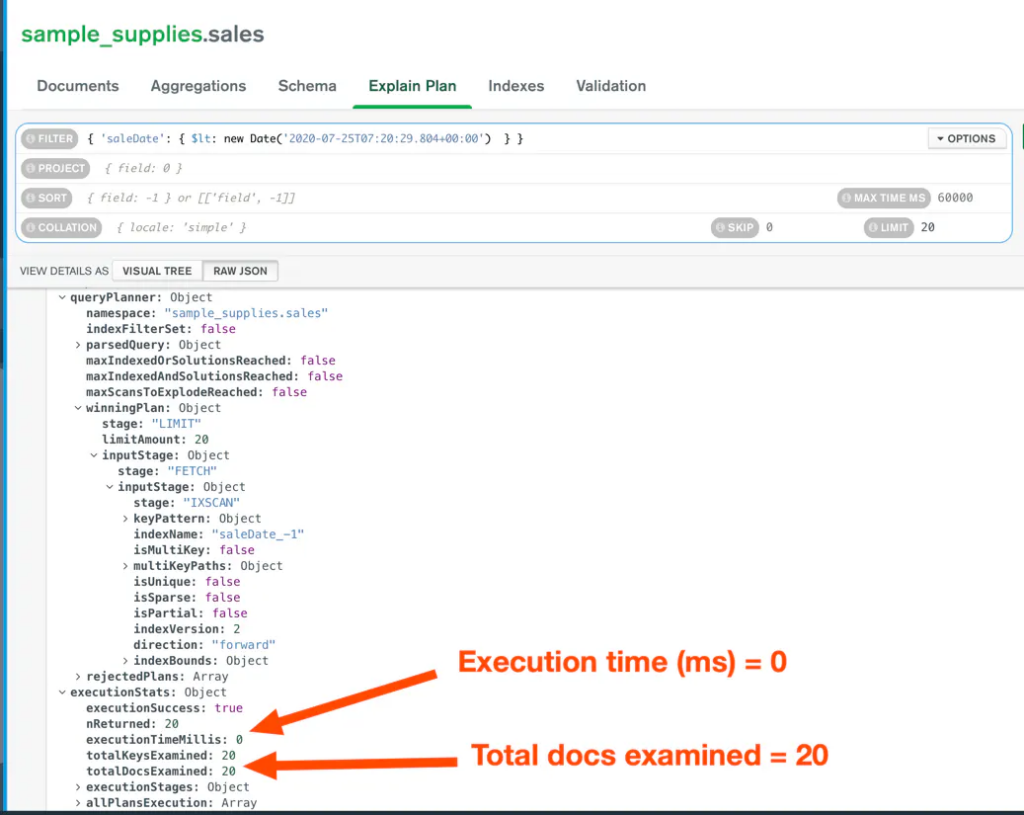
Không có gì đáng ngạc nhiên, đây là khoảng thời gian để API Expressjs của chúng ta trả về 20 tài liệu từ cùng một collection:
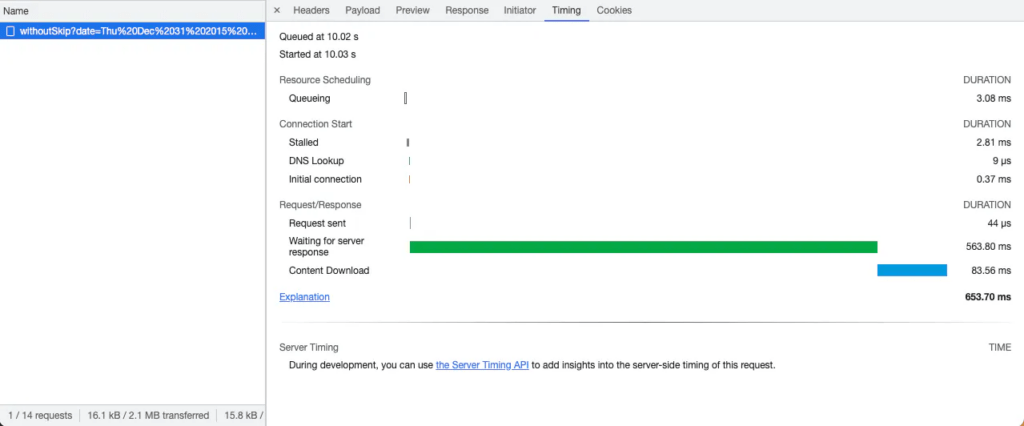
Bạn vẫn có thể cần phân trang offset
Mặc dù việc triển khai dựa trên con trỏ giành chiến thắng trong cuộc chiến về hiệu suất nhưng việc sử dụng phân trang dựa trên offset sẽ không gây hại gì nếu bạn đang xử lý một lượng dữ liệu tương đối nhỏ (ví dụ: các dự án cuối tuần).
Và nếu bạn đã từng thử triển khai cả hai, bạn sẽ biết rằng phân trang dựa trên offset sẽ trực quan và dễ thực hiện hơn nhiều. Mặt khác, con trỏ có thể phức tạp hơn một chút.
Mặc dù phân trang bù cũng có những sai sót khác (ví dụ: nguy cơ bỏ qua các tài liệu chưa đọc nếu việc xóa xảy ra trong khi bạn đang tìm nạp), thực tế hiếm khi dự án của bạn không có nhiều người dùng hoạt động.
Bây giờ bạn đã biết sự cân bằng, bạn có thể đưa ra quyết định dựa trên trường hợp sử dụng của mình.
Xem thêm bài viết của mình tại link


2 Replies to “Phân trang tốt hơn không dùng Offset”